Immutable Deployment Pattern for AM Configuration Without File- Based
Author: |
Darinder Shokar |
Created at: |
Sep 2019 |
Updated at: |
Dec 2024 |
Introduction
The standard production grade deployment pattern for ForgeRock Access Management (AM) is to use replicated sets of configuration directory server instances to store all of AM’s configurations. The deployment pattern has worked well in the past, but is less suited to the immutable, DevOps-enabled environments of today.
This article presents an alternative view of how an immutable deployment pattern could be applied to AM in lieu of the upcoming, full file-based configuration (FBC) for AM in version 7.0 of the ForgeRock Identity Platform. This pattern could also support an easier transition to FBC.
Current, common deployment pattern
Currently, most customers deploy AM with externalized configuration, core token service (CTS), and userstore instances.
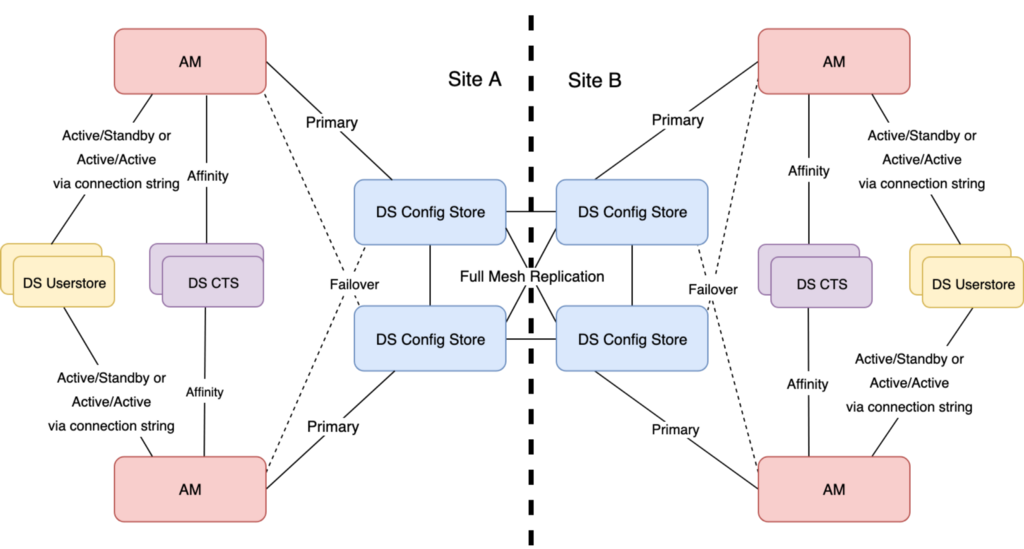
The following diagram illustrates such a topology spread over two sites.
The focus is on the DS config stores; hence, the CTS and ForgeRock
Directory Server (DS) userstore connections and replication topology
have been simplified. Note that this blog is still applicable to
deployments which are single site:
Dual site AM deployment pattern. Focus is on the DS Configuration stores
In this topology, AM uses connection strings to the DS config stores to enable an all active config store architecture, with each instance of AM targeting one DS config store as primary, and the second as failover per site. Note that in this model there is no cross-site failover for AM to config stores connections (possible, but discouraged). The DS config stores do communicate across site for replication to create a full mesh, as do the user and CTS stores.
A slight divergence from this model, and one applicable to cloud environments, is to use a load balancer between AM and it’s DS config stores. We have observed that many customers experience problems with features such as persistent searches failing due to dropped connections. Hence, wherever possible, Consulting Services recommends the use of AM connection strings.
It should be noted that the use of AM connection strings specific to each AM instance can only be used if each AM instance has a unique, FQDN; for example, https://openam1.example.com:8443/openam, https://openam2.example.com:8443/openam and so on.
For more on AM Connection Strings, click here.
Problem Statement
This model has worked well in the past; the DS config stores contain all the stuff AM needs to boot and operate, plus a handful of runtime entries.
However, times are a changing!
The advent of Open Banking introduces potentially hundreds of thousands of OAuth2 clients, AM policies entry numbers are ever increasing and with UMA thrown in for good measure. The previously small, minimal footprint, fairly static DS config stores are suddenly much more dynamic and contain many thousands of entries. Managing the stuff AM needs to boot and operate and all this runtime data suddenly becomes much more complex.
TADA! Roll up the new DS app and policy stores. These new data stores address this by allowing separation from the stuff AM needs to boot and operate from long-lived, environment-specific data, such as policies, OAuth2 clients, SAML entities, and others. Nice!
However, one problem still remains; it is still difficult to do stack by stack deployments, blue/green type deployments, rolling deployments, and/or support immutable style deployments, as DS config store replication is in place, and needs to be very carefully managed during deployment scenarios.
Some common issues:
-
Making a change to one AM instance can quite easily have a ripple effect through DS replication, which impacts and/or impairs the other AM nodes both within the same site or remote. This behavior can make customers more hesitant to introduce patches, config, or code changes.
-
In a dual site environment, the typical deployment pattern is to stop cross-site replication, force traffic to site B, disable site A, upgrade site A, test it in isolation, force traffic back to the newly deployed site A, ensure production is functional, disable traffic to site B, push replication from site A to site B, reenable replication, and upgrade site B before finally returning to normal service.
-
Complexity is further increased if app and policy stores are not in use as the in-service DS config stores may have new OAuth2 clients, UMA data, and more created during the transition which need to be preserved. So, in the above scenario an LDIF export of site B’s DS config stores for such data needs to be taken and imported in site A prior to site A going live (to catch changes while site A deployed was in progress). After site B is disabled another LDIF export needs to taken from B and imported into A to catch any last minute changes between the first LDIF export, and the switch over. Sheesh!
-
Even in a single site deployment model, managing replication as well as managing the AM upgrade/deployment itself introduces risk and several potential break points.
New Deployment Model
The real enabler for a new deployment model for AM is the introduction of app and policy stores, which will be replicated across sites. They enable full separation from the stuff AM needs to boot and run from environmental runtime data. In such a model, the DS config stores return to a minimal footprint, containing only AM boot data with the app and policy stores containing the long-lived environmental runtime data, which is typically subject to zero loss SLAs and long-term preservation.
Another enabler is a different configuration pattern for AM, where each AM effectively has the same FQDN and serverId, allowing AM to be built once, and then cloned into an image, to allow rapid expansion and contraction of the AM farm without having to interact with the DS config store to add/delete new instances, or go through the build process again and again.
Finally, the last key component to this model is affinity-based load balancing for the userstore, CTS, app and policy stores to both simplify the configuration, and enable an all-active datastore architecture immune to data misses as a result of replication delay. This is central to this new model.
Affinity is a unique feature of the ForgeRock Identity Platform, and is used extensively by many customers. For more on affinity, click here.
The proposed topology below illustrates this new deployment model and is applicable to both active-active deployments and active-standby. Note cross site replication for the user, app and CTS stores is depicted, but for global/isolated deployments, may well not be required:
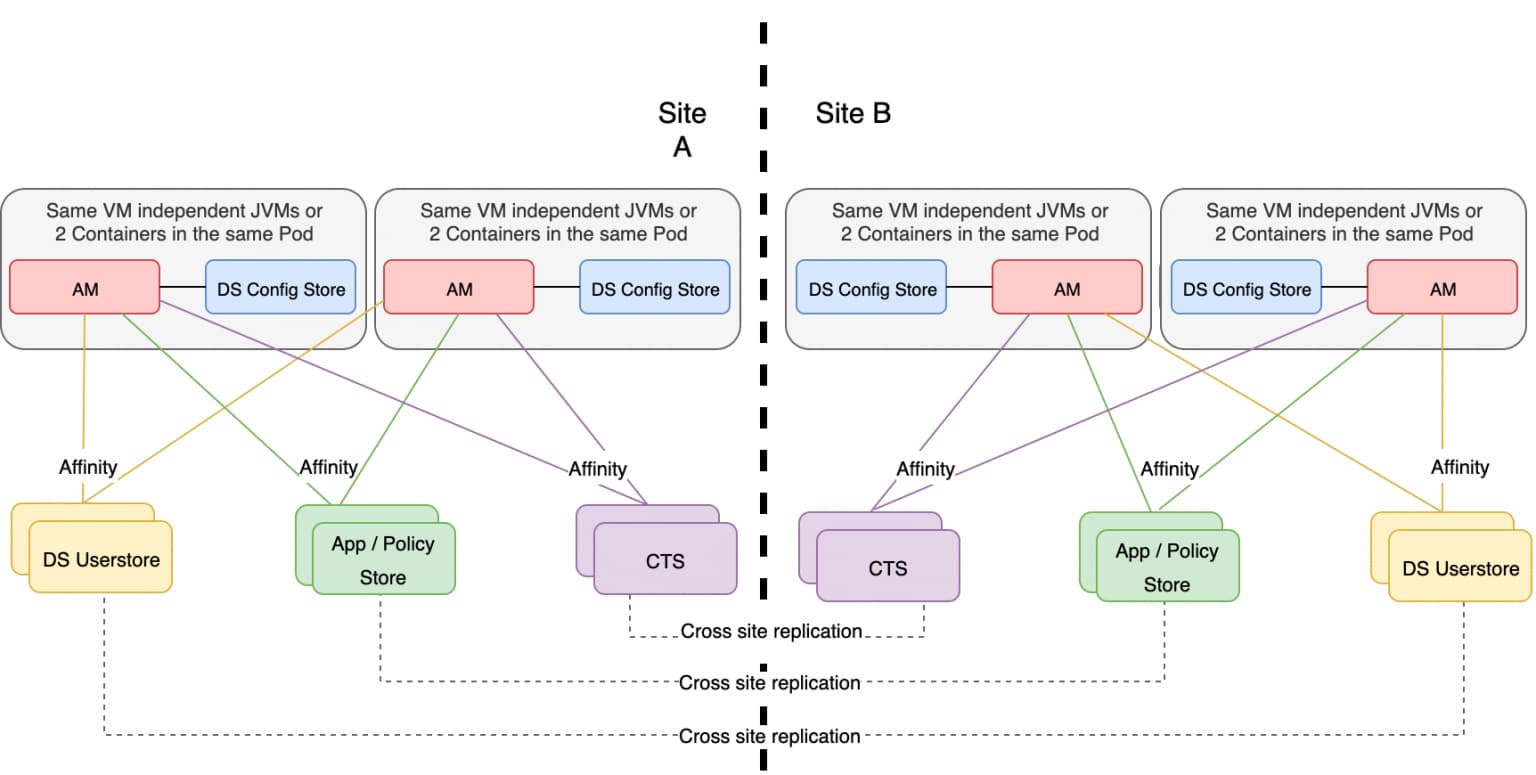
Localized DS config store for each AM instance, with replication disabled
As the DS config store footprint will be minimal, to enable immutable configuration and massively simplify step-by-step/blue green/rolling deployments, the proposal is to move the DS config stores local to AM with each AM instance built with exactly the same FQDN and serverId. Each local DS config store lives in isolation, and replication is not enabled between these stores.
In order to provision each DS config store, in lieu of replication, either the same build script can be executed on each host, or a quicker and more optimized approach would be to build one AM-DS config store instance/pod in full, clone it, and deploy the complete image to deploy a new AM-DS instance. The latter approach removes the need to interact with Amster to build additional instances, and, for example, to use Git to pull configuration artifacts. With this model, any new configuration changes require a new package/Docker image/AMI, and so on, and an immutable build.
At boot time AM, uses its local address to connect to its DS config store, and affinity to connect to the userstore, CTS, and the app/policy stores. Note — the use of embedded DS config stores, where a DS instance is deployed in the same JVM as AM, is not recommended.
Advantages of this model
-
As the DS config stores are not replicated, most AM configuration and code level changes can be implemented or rolled back (using a new image or similar) without impacting any of the other AM instances, and without the complexity of managing replication. Blue/green, rolling, and stack-by-stack deployments and upgrades are massively simplified, as is rollback.
-
It enables simplified expansion and contraction of the AM pool, especially if an image/clone of a full AM instance and the associated DS config instance is used. This cloning approach also protects against configuration changes in Git or other code repositories inadvertently rippling to new AM instances, as the same code and configuration base is deployment everywhere.
-
It promotes the “cattle vs. pet” paradigm, for any new configuration deploying a new image/package.
-
This approach does not require any additional instances; the existing DS config stores are repurposed as app/policy stores, and the DS config stores are hosted locally to AM (or in a small container in the same pod as AM).
-
The existing DS config store can be quickly repurposed as app/policy stores. No new instances or data-level deployment steps are required other than tuning up the JVM and potentially uprating storage, enabling rapid switching from DS Config to App/Policy Stores
-
The enabler for FBC: when FBC becomes available, the local DS config stores are simply stopped in favor of FBC. Also, if transition to FBC becomes problematic, rollback is easy — fire up the local DS config stores and revert back.
Disadvantages of this model
-
There is no DS config store failover. If the local DS config store fails, the AM instance connected to it would also fail and not recover. However, this fits well with the pets vs cattle paradigm; if a local component fails, kill the whole instance, and instantiate a new one.
-
Any log systems which have logic based on individual FQDNs for AM (Splunk, and others) would need their configuration to be modified to take into account, as each AM instance now has the same FQDN.
-
This deployment pattern is only suitable for customers who have mature DevOps processes. The expectation is no changes are made in production; instead, a new release/build is produced, and promoted to production. If, for example, a customer makes changes via REST or the UI directly, then these changes will not be replicated to all other AM instances in the cluster, which would severely impair performance and stability.
Conclusions
This suggested model would significantly improve a customer’s ability to take on new configuration/code changes, and potentially roll back without impacting other AM servers in the pool, make effective use of the app/policy stores without additional kits, allows easy transition to FBC, and enables DevOps-style deployments.
Other Articles by This Author
![]() Integrating IG with Identity
Cloud
[.badge-category__name#Integrations#]
Integrating IG with Identity
Cloud
[.badge-category__name#Integrations#]
Introduction It’s an exciting time here at ForgeRock. The ForgeRock Identity Cloud helps customers rapidly embrace next generation IAM, and quickly realize a return on their investment. For more on what this service offers, check out the following links: ForgeRock Identity Cloud overview here. ForgeRock Identity Cloud documentation here. In this exciting world, helping customers quickly and easily integrate with the ForgeRock Identity Cloud platform is critical. In this article, we’ll show yo…
Introduction ForgeRock Identity Cloud is revolutionizing the way businesses, consumers, and customers execute on their IAM strategy. Our Identity Cloud customers repeat three common feedback themes over and over again: Quicker time to value: Customers no longer have to worry about the build, run, operate and feed process of standing up an IAM system—ForgeRock Identity Cloud is managed by the people who build the underlying software; us (ForgeRock). Introduction of cool new stuff quicker and wi…
![]() A
Script for Executing the OAuth 2.0 Authorization Code Flow with PKCE in
AM [.badge-category__name#Setup#]
A
Script for Executing the OAuth 2.0 Authorization Code Flow with PKCE in
AM [.badge-category__name#Setup#]
Introduction I often meet customers who want to quickly understand how the OAuth2 Authorization Code grant type works, how Proof Key for Code Exchange (PKCE) works, and how they can execute the flows programatically to understand how it all hangs together. This blog provides a sample script to execute the OAuth2 Authorization Code grant flow, along with support for PKCE using cURL. What is the OAuth2 Authorization Code Grant Flow? The Authorization Code grant is a two-step interactive process …
![]() Locking
Out a User and Deleting All of Their Active Tokens in AM
[.badge-category__name#Maintenance#]
Locking
Out a User and Deleting All of Their Active Tokens in AM
[.badge-category__name#Maintenance#]
Introduction Customers often ask, “We have a business security requirement where we want to not only lock a given user out of the system, but also find and delete all SSO tokens they have created using the AM API. How do we do that?” This article shows you how to do this using the delete_tokens.sh script ;) In order to achieve this, we’ll be making using of the following AM endpoints: …/authenticate: Endpoint for authenticating users. …/users: Endpoint for getting and setting user profile at…