The Basics of Developing Scripted Connectors for Java Remote Connector
Author: |
Konstantin Lapine |
Created at: |
Jun 2023 |
Updated at: |
Dec 2023 |
The Basics of Developing Scripted Connectors for Java Remote Connector Server (Part 2 of 2)
Use the links under the Contents section to quickly navigate to an area of interest. If you feel lost in a long chapter, navigate to the closest Back to contents link and try again.
The quoted paragraphs, such as this one, indicate that the content they provide is supplementary and optional.
##Contents
-
Scripted Groovy Connector (Toolkit)
-
-
Choosing IDE
-
Interacting with RCS via IDM’s REST
-
Debugging Scripts
-
Try and Catch
-
Custom Logs
-
Attaching Debugger to Kubernetes Deployment
-
Enable Debugging
-
Enable Debugging Port
-
Configure Debugger and Start Debugging
-
-
Attaching Debugger to RCS within Docker Container
-
-
Scripting Context
-
Bindings
-
Global Variables
-
-
Scripted Groovy Connector Bindings
-
configuration
-
configuration.propertyBag
-
In Connection Configuration
-
In Customizer Script
-
For Groovy Connector
-
For Scripted SQL Connector
-
For Scripted REST Connector
-
-
In Scripts at Runtime
-
-
-
-
Scripted Groovy Connection Configuration
-
“configurationProperties”
-
“customConfiguration” and “customSensitiveConfiguration”
-
-
“systemActions”
-
Defining System Action
-
“scriptId”
-
“actions”
-
“systemType”
-
“actionType”
-
“actionSource” or “actionFile”
-
-
-
Invoking via IDM’s REST
-
Parts of the Request
-
/openidm/system/<connection-name> (connection endpoint)
-
?_action=script (request to execute script)
-
&scriptId=<script_id> (system action to execute and return from)
-
&arg1=value1&arg2=value2 . . . (script arguments)
-
request body (script arguments)
-
&scriptExecuteMode=resource (“run on resource”)
-
Executed Script
-
Context of Executed Script
-
Evaluating
scriptText -
Other Applications of
scriptText
-
-
-
-
Invoking from an IDM Script
-
Syntax
-
Examples
-
“run on connector”
-
“run on resource”
-
-
-
“run on resource” vs “run on connector”
-
Support in Connectors
-
-
-
##Scripted Groovy Connector (Toolkit)
The scripted connectors on a Java connector server are based on the Groovy Connector Toolkit. Out of the box, ICF bundles the following scripted connectors:
-
Groovy (
org.forgerock.openicf.connectors.groovy.Scripted(Poolable)Connector)All connector operations are implemented in Groovy, with no built in support for a particular data source type.
-
Scripted REST (
org.forgerock.openicf.connectors.scriptedrest.ScriptedRESTConnector)The scripts are provided with automatically maintained by ICF customizable connection to a REST interface.
-
Scripted SQL (
org.forgerock.openicf.connectors.scriptedsql.ScriptedSQLConnector)The scripts are provided with automatically maintained by ICF connection to a JDBC data source.
##Scripted Connectors > Registering Connection in IDM
A Groovy Toolkit-based connector will perform ICF Operations with scripts hosted on the connector server. Often, a connector is performing synchronization between the target and destination systems that employs many or all of the ICF operations. The location of the scripts needs to be reflected in the connection configuration.
Here, connection configuration is the final JSON sent to the
/openidm/config/provisioner.openicf/<connection-name>endpoint to register your connector parameters in IDM, as described in Configure connectors over REST.
There are cases when a connector may be used for a less involved task or a demo behind the remote source authorization walls, which might require less configuration details.
This section aims to describe registering a connection in IDM that will allow you to start using your scripted connector.
##Scripted Groovy Connector (Toolkit) > Registering Connection in IDM > Deployment Requirements
Before you can register a connection in IDM, your connector server usually needs to provide a certain infrastructure, to which your connector configuration will refer via the “configurationProperties” keys.
-
“scriptRoots”
An array of string references to locations on the connector server containing Groovy scripts that will be performing the ICF Operations. As noted in the Connector Reference docs, “scriptRoots” are required for all Groovy-based connectors.
For example, on your RCS,
/opt/openicf/scripts/groovypath could point to a folder with the scripts used by a connection. Then, the connection configuration may look like the following:provisioner.openicf-groovy.json{ "connectorRef": { "bundleName": "org.forgerock.openicf.connectors.groovy-connector", "connectorName": "org.forgerock.openicf.connectors.groovy.ScriptedConnector" [ . . . ] }, "configurationProperties": { "scriptRoots": [ "/opt/openicf/scripts/groovy" ], "createScriptFileName": null, "customizerScriptFileName": "CustomizerScript.groovy", "deleteScriptFileName": null, "resolveUsernameScriptFileName": null, "schemaScriptFileName": "SchemaScript.groovy", "searchScriptFileName": "SearchScript.groovy", "scriptOnResourceScriptFileName": "ScriptOnResourceScript.groovy", "syncScriptFileName": null, "testScriptFileName": null, "updateScriptFileName": null, [ . . . ] }, [ . . . ] }“scriptRoots” could also refer to a (connector)
.jarfile containing the scripts.For example:
provisioner.openicf-groovy.json[ . . . ] "scriptRoots" : [ "jar:file:connectors/groovy.jar!/scripts/" ] [ . . . ]For a functional scripted Groovy connection you MUST have a location registered in “scriptRoots”.
In order to run any scripts hosted on the connector server and referenced in the connection configuration, the scripts MUST exist under a location registered in “scriptRoots”.
If you provide an invalid reference to a script, your connection configuration will fail to be validated.
-
“customizerScriptFileName”
The file name of a script implementing custom configuration initialization.
This is a required script for Scripted REST connector.
-
“schemaScriptFileName”
The file name of a script implementing the Schema operation.
In order to use your connector for synchronization, you need a functional schema script correctly referenced in the connection configuration. Also, a functional schema script returning a schema object is required if you register your connection as described in the Configure connectors over REST doc.
Schema script functionality is described in details in the Schema Script chapter, and example implementations can be found in its Schema Script > Example Schema Script section.
-
“searchScriptFileName”
A connection provides access to a remote system. Normally, it is used for data exchange, where remote data is a list of resources obtained from a search operation. In a Groovy Toolkit-based connector, the search operation is performed with a search or query script, which is referenced in the connection configuration via the “searchScriptFileName” key.
In order to use your connector for the search operation, including CRUD operations and synchronization, you MUST have a functional search script correctly referenced in the connection configuration.
Search script functionality is described in details in the Search Script chapter, and example implementations can be found in the Example Search Script section.
If you plan to implement any other ICF operations with Groovy scripts, you will need to deploy the corresponding scripts as well.
In addition, a UI might impose its own requirements while registering a connection.
##Scripted Connectors > Registering Connection in IDM > Platform UI
In the Platform admin UI, you can Register an application and configure a Groovy, Scripted REST, or Scripted (SQL) Table connection on the application’s Provisioning tab.
From the Provisioning tab, you will be able to manage your connection, see the remote object classes and data, and apply outbound and/or inbound mappings.
A connection created in this way will also appear in the IDM admin UI, but changes made in the IDM’s native console might not apply correctly to the Platform application.
##Scripted Connectors > Registering Connection in IDM > IDM’s REST
You can register and manage your scripted Groovy connection over IDM’s REST. This way, you will miss the new Application Management features available in the Platform admin UI. You will, however, be able to manage your connection in a reproducible way and in conjunction with your script development. It will also allow for registering a minimal configuration that will still render a functional scripted connector or employ functionality a UI might not have access to.
##Scripted Connectors > Registering Connection in IDM > IDM’s REST > Create Configuration
As described in the Configure connectors over REST doc, in order to register a connection, you will need to perform the following steps:
-
Find a connector reference in data returned from
/openidm/system?_action=availableConnectors -
Using the connector reference, request the connector’s core configuration from
/openidm/system?_action=createCoreConfig. -
Update the core configuration with your RCS specifics, and get the full connection configuration from
/openidm/system?_action=createFullConfig.Optionally, update the full connector configuration with entries not provided by default, such as “systemActions”.
-
Using the full configuration, register a connection at its designated configuration endpoint:
/openidm/config/provisioner.openicf/<connection-name>.
As explained in the Scripted Groovy Connector (Toolkit) > Deployment Requirements chapter, in the Step 3 of this process, under the “configurationProperties” key, you will need to provide a “scriptRoots” entry and valid references to the scripts that you plan to employ in your connector.
To create a full connection configuration in the Step 3, at a minimum, you will need to update the core config with the following references:
-
org.forgerock.openicf.connectors.groovy.ScriptedConnector-
“configurationProperties.scriptRoots”
-
“configurationProperties.schemaScriptFileName”
The referenced schema script file MUST exist under a location listed in “scriptRoots” and the script MUST return a schema object, as described in the the Schema Script chapter.
-
-
org.forgerock.openicf.connectors.scriptedrest.ScriptedRESTConnector-
“configurationProperties.serviceAddress”
-
“coreConfig.configurationProperties.username”
-
“configurationProperties.password”
-
“configurationProperties.scriptRoots”
-
“configurationProperties.customizerScriptFileName”
The referenced customizer script file MUST exist under a location listed in “scriptRoots” and the script MUST define the
initclosure. Which means it needs to callcustomizemethod, pass in a closure, inside which it needs to callinitmethod and pass in a closure (in which the HTTP client used in the connector’s scripts could be customized).For example:
customize { init { [ . . . ] } } -
“configurationProperties.schemaScriptFileName”
The referenced schema script file MUST exist under a location listed in “scriptRoots” and the script MUST return a schema object, as described in the the Schema Script chapter.
-
-
org.forgerock.openicf.connectors.scriptedsql.ScriptedSQLConnector-
“configurationProperties.url”
-
“configurationProperties.username”
-
“configurationProperties.password”
-
“configurationProperties.driverClassName”
-
“configurationProperties.scriptRoots”
-
“configurationProperties.schemaScriptFileName”
The referenced schema script file MUST exist under a location listed in “scriptRoots” and the script MUST return a schema object, as described in the the Schema Script chapter.
Note that a functional Scripted SQL connector configuration requires valid connection parameters and a functional connection they refer to.
-
##Scripted Connectors > Registering Connection in IDM > IDM’s REST > Use a Provisioner File
Once you have your connection configuration in JSON format—received either from the Step 3, Step 4, or an existing connection configuration endpoint—you can save it in a file, track it in your source, and read it from a script to register or update a connection.
For example:
register-connection.sh
# @param {string} $1 - Path to the provisioner configuration file.
# @param {string} $2 - Name of the connection, as (it will be) registered at /openidm/system/<connection-name>.
curl \
--header "Authorization: $AUTHORIZATION_HEADER_VALUE" \
--header "Accept-API-Version: resource=1.0" \
--header "Content-Type: application/json" \
--request PUT \
--data "$(cat $1)" \
"$TENANT_ORIGIN/openidm/config/provisioner.openicf/$2" -i
You can also craft your provisioner file manually, which is even less restrictive than creating the full connection configuration in the Configure connectors over REST process.
##Scripted Connectors > Registering Connection in IDM > IDM’s REST > Example
As outlined in the Interacting with RCS via IDM’s REST chapter, while developing your Groovy connector, one convenient option for interacting with a connection configuration endpoint might be your browser console.
For example:
IDM admin UI browser console
/**
* Register a Groovy connection.
* @todo Sign in IDM admin UI and run this script in the browser console.
*/
(async function () {
// Step 0
/**
* @todo Name the connection endpoint in IDM REST (case-sensitive, /[a-zA-Z0-9]/).
* This will define the path under which you will interact with your remote connector system object.
* @example
* var connectionName = 'groovy'
*
* Then, the system object endpoint path will be:
* '/openidm/system/groovy'
*/
var connectionName = 'groovy'
/**
* @todo Identify your RCS server or server cluster
* as it had been registered in your Platform admin UI > Identities > Connect.
*/
var connectorServerName = 'rcs';
// Step 1
/**
* @todo Identify the connector name, for which you want to register a connection.
*/
var connectorName = 'org.forgerock.openicf.connectors.groovy.ScriptedConnector';
/**
* Get available connectors.
*/
var settings = {
method: 'POST',
url: '/openidm/system?_action=availableConnectors'
};
var connectorRef = await $.ajax(settings);
console.log('connectorRef', JSON.stringify(connectorRef, null, 4));
/**
* Get the connector reference.
*/
connectorRef = connectorRef.connectorRef.find((connectorRef) => {
return connectorRef.connectorName === connectorName && connectorRef.connectorHostRef === connectorServerName;
});
console.log('connectorRef', JSON.stringify(connectorRef, null, 4));
if (!connectorRef) {
throw(`Cannot find ${connectorName} on host named ${connectorServerName}.`);
}
// Step 2
/**
* Generate the connector's core configuration.
*
* (Optional) Sort configuration properties for easy navigation and comparison:
* @example JavaScript
* coreConfig.configurationProperties = Object.entries(coreConfig.configurationProperties).sort().reduce((object, [key, value]) => {
* object[key] = value;
* return object;
* }, {});
*/
settings = {
headers: {
'Content-Type': 'application/json'
},
method: 'POST',
url: '/openidm/system?_action=createCoreConfig',
data: JSON.stringify({
connectorRef: connectorRef
})
};
var coreConfig = await $.ajax(settings);
console.log('coreConfig', JSON.stringify(coreConfig, null, 4));
// Step 3
/**
* Generate full, source-specific configuration.
* For that, add necessary information to the core configuration.
*/
coreConfig.configurationProperties.scriptRoots = [
`/opt/openicf/scripts/groovy`
];
coreConfig.configurationProperties.schemaScriptFileName = 'SchemaScript.groovy';
coreConfig.configurationProperties.searchScriptFileName = 'SearchScript.groovy';
settings = {
headers: {
'Accept-API-Version': 'resource=1.0',
'Content-Type': 'application/json'
},
method: 'POST',
url: '/openidm/system?_action=createFullConfig',
data: JSON.stringify(coreConfig)
};
var fullConfig = await $.ajax(settings);
console.log('fullConfig', JSON.stringify(fullConfig, null, 4));
// optional
/**
* Update the full configuration with additional settings.
*/
fullConfig.systemActions = [
{
"scriptId" : "script-1",
"actions" : [
{
"systemType" : ".*ScriptedConnector",
"actionType" : "groovy",
"actionSource" : "2 + 2;"
},
{
"systemType" : ".*Scripted.*Connector",
"actionType" : "groovy",
"actionSource" : "2 * 2"
}
]
}
];
console.log('fullConfigUpdated', JSON.stringify(fullConfig, null, 4));
// Step 4
/**
* Register the connection.
*/
settings = {
headers: {
'Content-Type': 'application/json'
},
method: 'PUT',
url: `/openidm/config/provisioner.openicf/${connectionName}`,
data: JSON.stringify(fullConfig)
};
var connection = await $.ajax(settings);
console.log('connection', JSON.stringify(connection, null, 4));
}());
You can update an existing connection by using its configuration endpoint.
For example:
IDM admin UI browser console
/**
* Update a Groovy connection.
* @todo Sign in IDM admin UI and run this script in the browser console.
*/
(async function () {
/**
* @todo Provide name of the connection endpoint in IDM's REST (case-sensitive).
*/
var connectionName = 'groovy'
/**
* Get connection configuration.
*/
settings = {
url: `/openidm/config/provisioner.openicf/${connectionName}`
};
var connectionConfig = await $.ajax(settings);
console.log('connectionConfig', JSON.stringify(connectionConfig, null, 4));
/**
* Update connection configuration.
*/
connectionConfig.systemActions = [
{
"scriptId" : "script-1",
"actions" : [
{
"systemType" : ".*Scripted.*Connector",
"actionType" : "groovy",
"actionSource" : "2 * 2"
}
]
}
];
/**
* Update connection.
*/
settings = {
headers: {
'Content-Type': 'application/json'
},
method: 'PUT',
url: `/openidm/config/provisioner.openicf/${connectionName}`,
data: JSON.stringify(connectionConfig)
};
var connection = await $.ajax(settings);
console.log('connection', JSON.stringify(connection, null, 4));
}());
##Scripted Groovy Connector (Toolkit) > Schema Script
In order to be functional, your schema script MUST return an instance of Schema.
The schema instance MUST be populated with one or more instances of ObjectClassInfo, each representing a data object class (type) that you decided to expose via your connector.
To define a connector schema, you can call
builder.schema(Closure closure) method in your schema script.
Inside the closure passed into the builder.schema(Closure closure)
method, you can call objectClass(Closure closure) method. Each call to
this method will create an
ObjectClassInfo
instance and add it to your connector schema; thus, defining an object
class. Since at least one object class needs to be present in a schema,
you need to call the objectClass(Closure closure) method at least
once.
If you pass an empty closure into the objectClass(Closure closure)
method, the resulting object class instance will be of the default
ACCOUNT type and have the default attribute NAME.
For example:
SchemaScript.groovy
builder.schema {
objectClass {
}
}
When a connection is registered, as described in the Registering Connection in IDM chapter, you will be able to request its schema in a UI or via IDM’s REST:
/openidm/system/<connection-name>?_action=schema
You cannot request a connector schema from an IDM script, because
schemaaction in scripts is not supported on system resources.
For example:
IDM admin UI browser console
(async function () {
var data = await $.ajax('/openidm/system/groovy?_action=schema', {
method: 'POST'
});
console.log(JSON.stringify(data, null, 4));
}());
The aforementioned minimal example of a schema definition would result in the following response:
{
"objectTypes": {
"__ACCOUNT__": {
"$schema": "http://json-schema.org/draft-03/schema",
"id": "__ACCOUNT__",
"type": "object",
"nativeType": "__ACCOUNT__",
"properties": {
"__NAME__": {
"type": "string",
"nativeName": "__NAME__",
"nativeType": "string"
}
}
}
},
"operationOptions": {
[ . . . ]
}
}
Note:
-
A connector schema contains two keys:
-
“objectTypes”
-
“operationOptions”
By default, operation options associated with an object class have no properties (that is, no options) defined. At the time of this writing, adding operation options in a schema script is not supported.
-
-
The “objectTypes” key is populated with a single object class definition of
ACCOUNTtype with a single string attributeNAME.
##Scripted Groovy Connector (Toolkit) > Schema Script > Object Classes
##Scripted Groovy Connector (Toolkit) > Schema Script > Object Classes > objectClass(Closure closure) method
To customize your schema, inside the closure passed into the
builder.schema(Closure closure) method you can call its delegate’s
objectClass(Closure closure) method. In turn, this method accepts a
closure, inside which you can use methods defined in its delegate to
describe a custom object class:
-
[heading—developing-scripted-connectors-groovy-schema-object-types-object-class-type]#
type(String type)Internally, this will call the ObjectClassInfoBuilder.setType(java.lang.String type) method.
The string that you provide as the argument will serve as the object class name. This will become an option under Applications > connection name > Provisioning > Connector Type (form) in the Platform admin UI, and under CONFIGURE > CONNECTORS > connection-name > Object Types and Data in IDM admin UI.
For example:
type 'myObjectTypeName'
If you don’t call the
type(String type)method, and thus don’t set the type explicitly, by default, it will be populated with “ACCOUNT” string, which is the value of theACCOUNT_NAMEconstant predefined in the ObjectClass class.An “ACCOUNT” instance of ObjectClassInfo “represents a human being in the context of a specific system or application”.
Hence, in the schema script example above, where the object class definition represents users of the target system, you could leave the type name at its default. Setting it to an arbitrary name makes it more explicit and demonstrates the use of the
type(String type)method. -
[heading—developing-scripted-connectors-groovy-schema-object-types-object-class-attribute]#
attribute(String name[, Class type[, Set flags]])This method will define an attribute (that is, a property) for the remote object class. You have to pass in at least the attribute name. In addition, you can reference a desired attribute’s Java type (which by default is
java.lang.String) and provide a Set of attribute flags—all in that order.For example:
attribute 'myAttributeName1', Boolean.class, EnumSet.of(REQUIRED, MULTIVALUED)
The exact syntax is described in the Java documentation for the
build(String name[, Class type[, Set flags]])methods of the AttributeInfoBuilder class, which is used internally for constructing a staticAttributeInfoobject from the provided arguments.Eventually, it will call the ObjectClassInfoBuilder.addAttributeInfo(AttributeInfo info) method before building the object class instance.
-
[heading—developing-scripted-connectors-groovy-schema-object-types-object-class-attribute-info]#
attribute(AttributeInfo attributeInfo)You can pass in an AttributeInfo instance to the
attributemethod as the only argument that will fully define your attribute. This way, a commonly used attribute can be defined once and then included in different object classes.For example:
SchemaScript.groovyimport static org.identityconnectors.framework.common.objects.AttributeInfo.Flags.MULTIVALUED import static org.identityconnectors.framework.common.objects.AttributeInfo.Flags.NOT_UPDATEABLE import static org.identityconnectors.framework.common.objects.AttributeInfo.Flags.REQUIRED import static org.identityconnectors.framework.common.objects.AttributeInfo.Flags.NOT_RETURNED_BY_DEFAULT import org.identityconnectors.framework.common.objects.AttributeInfoBuilder def myAttributeName1AttributeInfo = AttributeInfoBuilder.build( 'myAttributeName1', String.class, EnumSet.of(REQUIRED, MULTIVALUED, NOT_UPDATEABLE, NOT_RETURNED_BY_DEFAULT) ) objectClass { type 'myObjectTypeName1' attribute myAttributeName1AttributeInfo [ . . . ] } objectClass { type 'myObjectTypeName2' attribute myAttributeName1AttributeInfo [ . . . ] }If you define attribute instances in a shared location, you will be able to use methods of the AttributeInfo class to retrieve the attribute properties in other scripts.
-
[heading—developing-scripted-connectors-groovy-schema-object-types-object-class-attributes]#
attributes(Closure closure)This method takes a closure as its only argument and can define multiple attributes for the object class at once.
In each statement in the closure, the first literal, which acts as a method call, serves as the attribute’s “nativeName”, which is also how the attribute appears in the admin UIs.
The literal could be followed by one or more comma-separated arguments—all optional and in any order: Class
typeAttributeInfo.Flagsflag+ For example:
+
attributes { myAttributeName2() myAttributeName3 Boolean.class myAttributeName4 NOT_UPDATEABLE, MULTIVALUED myAttributeName5 Map.class, NOT_RETURNED_BY_DEFAULT myAttributeName6 MULTIVALUED, Map.class }+
In the closure, each statement represents a call to the ObjectClassInfoBuilder.addAttributeInfo(AttributeInfo info) method, and the line content is used for building an instance of the AttributeInfo class.
+ Note that if you don’t provide any arguments after the attribute name literal, you have to indicate that it is a method call by adding parenthesis:
+
myAttributeName2()
A String type NAME attribute is always added to each object class
in addition to properties defined with the
attribute(String name[, Class type[, Set flags]]) and/or
attributes(Closure closure) methods. The NAME attribute is
supposed to represent
user-friendly
identifier of an object on the target resource and could serve as a
placeholder for username.
##Scripted Groovy Connector (Toolkit) > Schema Script > Object Classes > defineObjectClass(ObjectClassInfo objectClassInfo[, . . . ])
You can also define object classes by using the
defineObjectClass(ObjectClassInfo objectClassInfo[, java.lang.Class<? extends SPIOperation>… operations)]
method of the
SchemaBuilder
class inside the closure passed into the
builder.schema(Closure closure) method.
For example:
SchemaScript.groovy
import org.identityconnectors.framework.common.objects.ObjectClassInfoBuilder
import org.identityconnectors.framework.common.objects.AttributeInfoBuilder
[ . . . ]
def myAttributeName1AttributeInfo = (new AttributeInfoBuilder()).build(
'myAttributeName1',
String.class,
EnumSet.of(REQUIRED, MULTIVALUED, NOT_UPDATEABLE, NOT_RETURNED_BY_DEFAULT)
)
def objectClassInfoBuilder = new ObjectClassInfoBuilder()
objectClassInfoBuilder.setType 'myObjectTypeName3'
objectClassInfoBuilder.addAttributeInfo myAttributeName1AttributeInfo
def myObjectTypeName3ObjectClassInfo = objectClassInfoBuilder.build()
defineObjectClass myObjectTypeName3ObjectClassInfo
A potential advantage of this approach is that you could cache and re-use your object definitions and a cleaner syntax for creating dynamically defined schema.
##Scripted Groovy Connector (Toolkit) > Schema Script > Example Data
To illustrate functionality of a scripted Groovy connector that employs the search operation, the following two data samples will be assumed:
-
[heading—developing-scripted-connectors-groovy-schema-example-data-users]#
Sample Users Data{ "Resources": [ { "id": "2819c223-7f76-453a-919d-413861904646", "userName": "bjensen", "displayName": "Ms. Barbara J Jensen III", "name": { "familyName": "Jensen", "givenName": "Barbara", "middleName": "Jane" }, "emails": [ { "value": "bjensen@example.com", "type": "work", "primary": true }, { "value": "babs@jensen.org", "type": "home" } ], "schemas": [ "urn:ietf:params:scim:schemas:core:2.0:User" ] }, [ . . . ] ], "itemsPerPage": 25, "schemas": [ "urn:ietf:params:scim:api:messages:2.0:ListResponse" ], "startIndex": 1, "totalResults": 25 }This sample data is a partial realization of the System for Cross-domain Identity Management (SCIM) User Resource Schema.
-
[heading—developing-scripted-connectors-groovy-schema-example-data-groups]#
Sample Groups Data{ "Resources": [ { "schemas": [ "urn:ietf:params:scim:schemas:core:2.0:Group" ], "id": "e9e30dba-f08f-4109-8486-d5c6a331660a", "displayName": "Tour Guides", "members": [ { "value": "2819c223-7f76-453a-919d-413861904646", "$ref": "https://example.com/v2/Users/2819c223-7f76-453a-919d-413861904646", "display": "Babs Jensen" }, [ . . . ] ] } ], "schemas": [ "urn:ietf:params:scim:api:messages:2.0:ListResponse" ], "totalResults": 1, "startIndex": 1, "itemsPerPage": 100 }This sample data is a partial realization of the SCIM Group Resource Schema.
##Scripted Groovy Connector (Toolkit) > Schema Script > Example Schema Script
Note that after registering your connection, any changes in a connector schema will not be automatically reflected in the IDM admin UI, until the object class is (re)added under CONFIGURE > CONNECTORS > connector name > Object Types. In the case of the Platform admin UI, currently, the entire application representing a scripted Groovy connection has to be recreated to reflect the changes.
##Scripted Groovy Connector (Toolkit) > Schema Script > Example Schema Script > Original Data Structure
To represent the
Users
and the
Groups
original data structures, you could define the following object
classes:
SchemaScript.groovy
/**
* Defined variables:
* builder org.forgerock.openicf.connectors.groovy.ICFObjectBuilder
* Provides schema(Closure closure) method for defining the connector schema.
* @see {@link https://backstage.forgerock.com/docs/openicf/latest/connector-dev-guide/scripts/script-schema.html#schema-builder}
* operation org.forgerock.openicf.connectors.groovy.OperationType
* The SEARCH operation type.
* configuration org.forgerock.openicf.connectors.groovy.ScriptedConfiguration
The connector configuration properties.
* @see {@link https://backstage.forgerock.com/docs/openicf/latest/connector-reference/groovy.html#groovy-connector-configuration}
* log org.identityconnectors.common.logging.Log
* Logging facility.
* @see {@link https://backstage.forgerock.com/docs/openicf/latest/_attachments/apidocs/org/identityconnectors/common/logging/Log.html}
* Returns org.identityconnectors.framework.common.objects.Schema
* @see {@link https://backstage.forgerock.com/docs/openicf/latest/_attachments/apidocs/org/identityconnectors/framework/common/objects/Schema.html}
*/
/**
* Import AttributeInfo.Flags constants, so that you can reference them in the code.
* @see {@link https://backstage.forgerock.com/docs/openicf/latest/_attachments/apidocs/org/identityconnectors/framework/common/objects/AttributeInfo.Flags.html}
* @example
* import static org.identityconnectors.framework.common.objects.AttributeInfo.Flags.*
*/
import static org.identityconnectors.framework.common.objects.AttributeInfo.Flags.MULTIVALUED
import static org.identityconnectors.framework.common.objects.AttributeInfo.Flags.NOT_UPDATEABLE
import static org.identityconnectors.framework.common.objects.AttributeInfo.Flags.REQUIRED
import static org.identityconnectors.framework.common.objects.AttributeInfo.Flags.NOT_RETURNED_BY_DEFAULT
builder.schema {
/**
* Define a custom object class of a custom type 'users'
* with provided by default __NAME__ attribute
* and five additional attributes
* describing its original data structure.
*/
objectClass {
type 'users'
attribute 'active', Boolean.class, EnumSet.of(REQUIRED)
attributes {
displayName()
name Map.class
emails Map.class, MULTIVALUED, REQUIRED
schemas MULTIVALUED, NOT_UPDATEABLE, NOT_RETURNED_BY_DEFAULT
}
}
/**
* Define an additional custom object class
* describing its original data structure.
*/
objectClass {
type 'groups'
attributes {
displayName()
members Map.class, MULTIVALUED, REQUIRED
schemas MULTIVALUED, NOT_UPDATEABLE, NOT_RETURNED_BY_DEFAULT
}
}
}
When defined in this way schema is requested via IDM’s REST:
IDM admin UI browser console
(async function () {
var data = await $.ajax('/openidm/system/groovy?_action=schema', {
method: 'POST'
});
console.log(JSON.stringify(data, null, 4));
}());
The response will contain the following “objectTypes”:
{
"objectTypes": {
"groups": {
"$schema": "http://json-schema.org/draft-03/schema",
"id": "groups",
"type": "object",
"nativeType": "groups",
"properties": {
"displayName": {
"type": "string",
"nativeName": "displayName",
"nativeType": "string"
},
"members": {
"type": "array",
"items": {
"type": "object",
"nativeType": "object"
},
"required": true,
"nativeName": "members",
"nativeType": "object"
},
"schemas": {
"type": "array",
"items": {
"type": "string",
"nativeType": "string"
},
"nativeName": "schemas",
"nativeType": "string",
"flags": [
"NOT_UPDATEABLE",
"NOT_RETURNED_BY_DEFAULT"
]
},
"__NAME__": {
"type": "string",
"nativeName": "__NAME__",
"nativeType": "string"
}
}
},
"users": {
"$schema": "http://json-schema.org/draft-03/schema",
"id": "users",
"type": "object",
"nativeType": "users",
"properties": {
"displayName": {
"type": "string",
"nativeName": "displayName",
"nativeType": "string"
},
"middleName": {
"type": "string",
"nativeName": "middleName",
"nativeType": "string"
},
"active": {
"type": "boolean",
"nativeName": "active",
"nativeType": "boolean"
},
"__NAME__": {
"type": "string",
"nativeName": "__NAME__",
"nativeType": "string"
},
"secondaryEmail": {
"type": "string",
"nativeName": "secondaryEmail",
"nativeType": "string",
"flags": [
"NOT_RETURNED_BY_DEFAULT"
]
},
"primaryEmail": {
"type": "string",
"nativeName": "primaryEmail",
"nativeType": "string"
},
"givenName": {
"type": "string",
"nativeName": "givenName",
"nativeType": "string"
},
"familyName": {
"type": "string",
"nativeName": "familyName",
"nativeType": "string"
}
}
}
},
"operationOptions": {
[ . . . ]
}
}
Note:
-
Attributes for the “users” object class are shown under its “properties” key in the response. The attributes are not necessarily in the order you have defined them.
-
In addition to the custom attributes, explicitly defined in the schema script, ICF will automatically add placeholders for the remote resource unique identifier (
_id, which is not shown in the response) and user-friendly identifier (NAME) to the schema. -
Adding AttributeInfo.Flags to an attribute definition will affect its behavior in ICF operations requested from IDM.
For example, adding the “NOT_RETURNED_BY_DEFAULT” flag would require the attribute to be explicitly requested from a search operation in order for it to be included in the search operation result.
##Scripted Groovy Connector (Toolkit) > Schema Script > Example Schema Script > Flat Representation of Data
A connector’s schema does not necessarily have to match the resource data structure—your search script can modify the original data to fit your schema definition.
For example, representing complex data types in the Users sample as individual string attributes will help with filtering search operation results, reduce dependency on transformation scripts, and make mapping and displaying the inbound data easier in the Platform and IDM admin UIs.
The example schema script below demonstrates this approach in the
users object class definition:
SchemaScript.groovy
/**
* Defined variables:
* builder org.forgerock.openicf.connectors.groovy.ICFObjectBuilder
* Provides schema(Closure closure) method for defining the connector schema.
* @see {@link https://backstage.forgerock.com/docs/openicf/latest/connector-dev-guide/scripts/script-schema.html#schema-builder}
* operation org.forgerock.openicf.connectors.groovy.OperationType
* The SEARCH operation type.
* configuration org.forgerock.openicf.connectors.groovy.ScriptedConfiguration
The connector configuration properties.
* @see {@link https://backstage.forgerock.com/docs/openicf/latest/connector-reference/groovy.html#groovy-connector-configuration}
* log org.identityconnectors.common.logging.Log
* Logging facility.
* @see {@link https://backstage.forgerock.com/docs/openicf/latest/_attachments/apidocs/org/identityconnectors/common/logging/Log.html}
* Returns org.identityconnectors.framework.common.objects.Schema
* @see {@link https://backstage.forgerock.com/docs/openicf/latest/_attachments/apidocs/org/identityconnectors/framework/common/objects/Schema.html}
*/
/**
* Import AttributeInfo.Flags constants, so that you can reference them in the code.
* @see {@link https://backstage.forgerock.com/docs/openicf/latest/_attachments/apidocs/org/identityconnectors/framework/common/objects/AttributeInfo.Flags.html}
* @example
* import static org.identityconnectors.framework.common.objects.AttributeInfo.Flags.*
*/
import static org.identityconnectors.framework.common.objects.AttributeInfo.Flags.MULTIVALUED
import static org.identityconnectors.framework.common.objects.AttributeInfo.Flags.NOT_UPDATEABLE
import static org.identityconnectors.framework.common.objects.AttributeInfo.Flags.REQUIRED
import static org.identityconnectors.framework.common.objects.AttributeInfo.Flags.NOT_RETURNED_BY_DEFAULT
builder.schema {
/**
* Define a custom object class of a custom type
* with provided by default __NAME__ attribute
* and seven additional attributes
* representing individual properties in primitive formats.
*/
objectClass {
type 'users'
attributes {
active Boolean.class
displayName()
givenName()
middleName()
familyName()
primaryEmail()
secondaryEmail NOT_RETURNED_BY_DEFAULT
}
}
/**
* Define an additional custom object class
* describing its original data structure.
*/
objectClass {
type 'groups'
attributes {
displayName()
members Map.class, MULTIVALUED, REQUIRED
schemas MULTIVALUED, NOT_UPDATEABLE, NOT_RETURNED_BY_DEFAULT
}
}
}
With this schema script, your search script is expected to handle the remote Users data in a way that all attribute values are returned as simple strings or a boolean in a search operation result. Doing so will be demonstrated in the Example Search Script > Flat Representation of Data chapter.
##Scripted Groovy Connector (Toolkit) > Search Script
If you plan to use search operation against your connector—for example, for synchronization—your search script needs to respond with available data. In order to be completely usable by IDM, a search script should implement filtering, sorting, and paging according to the criteria that was included in a search operation request and delivered to the script via its bindings.
To start working on your search script, you can deploy an empty one, so that you can reference it from your connection configuration, as described in the Registering Connection in IDM chapter. An empty search script that does not handle any data will mean query and read operations within IDM will always return an empty dataset.
##Scripted Groovy Connector (Toolkit) > Search Script > Requesting Search Operation
When your search script is deployed, you can update your connection configuration with a reference to the script, as described in the Registering Connection in IDM chapter, and request a search operation via IDM’s REST or from a script in IDM.
In either case, you MUST include some search criteria in your request. Optionally, you can add sorting and paging arguments and a list of attributes to receive.
##Scripted Groovy Connector (Toolkit) > Search Script > Requesting Search Operation > IDM’s REST
To initiate search operation using IDM’s REST, you can send a GET request to your system endpoint for an object class and include all your arguments in the URL.
-
Read Request
You can search for a single resource (that is, a record in the remote system data) with a ForgeRock Common REST (CREST) Read request. In this case, path to the resource ID endpoint will become the search criteria, and you won’t need any sorting or paging arguments. The simplest form of such request would have the following structure:
/openidm/system/<connection-name>/<object-class>/<ID>Optionally, you can specify a list of the object attributes to receive:
/openidm/system/<connection-name>/<object-class>/<ID>[?<attributes-to-receive>]For example:
/openidm/system/groovy/users/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx?_fields=NAME,displayName -
Query Request
You can request a list of resources by using CREST Query. The simplest form of such request would only include an all-inclusive “true” query definition:
/openidm/system/<connection-name>/<object-class>?_queryFilter=trueOptionally, you can request the result to be filtered, sorted, paged, and specify the object attributes to receive:
/openidm/system/<connection-name>/<object-class>?<query-definition>[&`<sorting-and-paging-arguments>`][&`<attributes-to-receive>`]For example:
/openidm/system/groovy/users?_queryFilter=true&_pageSize=4&_sortKeys=displayName,-NAME&_pagedResultsCookie=MjgxOWMyMjMtN2Y3Ni00NTNhLTkxOWQtNDEzODYxOTA0NjQ2&_fields=NAME,displayName
##Scripted Groovy Connector (Toolkit) > Search Script > Requesting Search Operation > IDM Script
-
Read Function
The simplest call to openidm.read(resourceName, params, fields) will only include an object class and a resource ID reference:
openidm.read('system/<connection-name>/<object-class>/<ID>');Optionally, you can specify a list of the object attributes to receive:
openidm.read( '/openidm/system/<connection-name>/<object-class>/<ID>', null, // optional and can be omitted if no attributes to receive are specified [ '<pointer>', // optional // [ . . . ] ] );For example:
IDM scriptconst data = openidm.read( 'system/groovy/users/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx', null, [ '__NAME__', 'displayName' ] ); -
Query Function
The simplest call to openidm.query(resourceName, params, fields) will only include an all-inclusive literal ‘true’:
openidm.query('system/<connection-name>/<object-class>', { _queryFilter: 'true' });Optionally, you can request the result to be filtered, sorted, paged, and specify the object attributes to receive:
openidm.query( '/openidm/system/<connection-name>/<object-class>', { '<query-definition>', '<sorting-and-paging-arguments>' // optional }, [ '<attributes-to-receive>' // optional ] );For example:
IDM scriptconst data = openidm.query( 'system/groovy/users', { _queryFilter: 'true', _pageSize: 4, _sortKeys: [ 'displayName', '-__NAME__' ], _pagedResultsCookie: 'MjgxOWMyMjMtN2Y3Ni00NTNhLTkxOWQtNDEzODYxOTA0NjQ2' }, [ 'displayName', '__NAME__' ] );Note that the
_queryFiltervalue MUST be a String.
You can validate your scripts over IDM’s REST.
For example:
IDM admin UI browser console(async function () { var script = ` try { const data = openidm.query( 'system/groovy/users', { _queryFilter: 'true' } ); data; } catch (e) { logger.error(String(e)); e.message; } `; var data = await $.ajax('/openidm/script?_action=eval', { method: 'POST', headers: { 'Content-Type': 'application/json' }, data: JSON.stringify({ type: 'text/javascript', source: script }) }); console.log(JSON.stringify(data, null, 4)); }());
##Scripted Groovy Connector (Toolkit) > Search Script > Responding with Data
As described in the
Search
or query script > Returning Search Results docs, to return a resource,
your script needs to call handler(Closure closure) or
handler(ConnectorObject connectorObject) method.
For example:
SearchScript.groovy
handler {
uid 'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx'
id 'firstname.lastname'
attribute 'active', true
attribute 'displayName', 'Firstname Lastname'
attribute 'givenName', 'Firstname'
attribute 'middleName', null
attribute 'familyName', 'Lastname'
attribute 'primaryEmail', 'firstname.lastname@example.com'
attribute 'secondaryEmail', 'firstname.lastname@example.org'
attribute 'notInSchema', 'Not in Schema'
}
A handler MUST include the
unique
identifier of an object within the name-space of the target resource as
the uid attribute for each resource. If your handler didn’t define
resource uid, you’d encounter an exception:
java.lang.IllegalArgumentException: The Attribute set must contain a 'Uid'
Each search operation result MUST also include the
user-friendly
identifier of an object on the target resource. In your handler, you
can provide this identifier as the id attribute; if omitted, it will
be populated automatically with the same value as the resource uid.
In addition to uid and id, which are required and will respectively
populate “_id” and “NAME” fields in the search operation result, the
handler method SHOULD also return all the other attributes defined in
the object class schema. Any attributes that are not explicitly included
in a handler call and any attributes that are not defined in the schema
will be omitted from the response.
The last script example calls the handler method once and thus will
always respond with a single resource data populated with the hardcoded
values, regardless of any criteria included in the search operation
request.
For example:
IDM admin UI browser console
(async function () {
var data = await $.ajax('/openidm/system/groovy/users?_queryFilter=true');
console.log(JSON.stringify(data, null, 4));
}());
With the Example Schema > Flat Representation of Data example deployed on the connector server, and referenced in the connection configuration, the response will look like the following:
{
"result": [
{
"_id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"__NAME__": "firstname.lastname",
"primaryEmail": "firstname.lastname@example.com",
"displayName": "Firstname Lastname",
"familyName": "Lastname",
"givenName": "Firstname",
"active": true
}
],
"resultCount": 1,
"pagedResultsCookie": null,
"totalPagedResultsPolicy": "NONE",
"totalPagedResults": -1,
"remainingPagedResults": -1
}
Note:
-
The result of a search operation in response to a query request is a list of objects.
-
The
uidandidattributes defined in the search script populate “_id” and “NAME” fields in the result. -
The
secondaryEmailattribute is omitted from the result, because it is marked with theNOT_RETURNED_BY_DEFAULTflag in the connector schema defined in the Example Schema Script, and the attribute was not explicitly requested. -
The
notInSchemaattribute is omitted from the result, because it was not defined in theusersobject class in the example schema.
In the Platform admin UI, these result could appear in the following way:
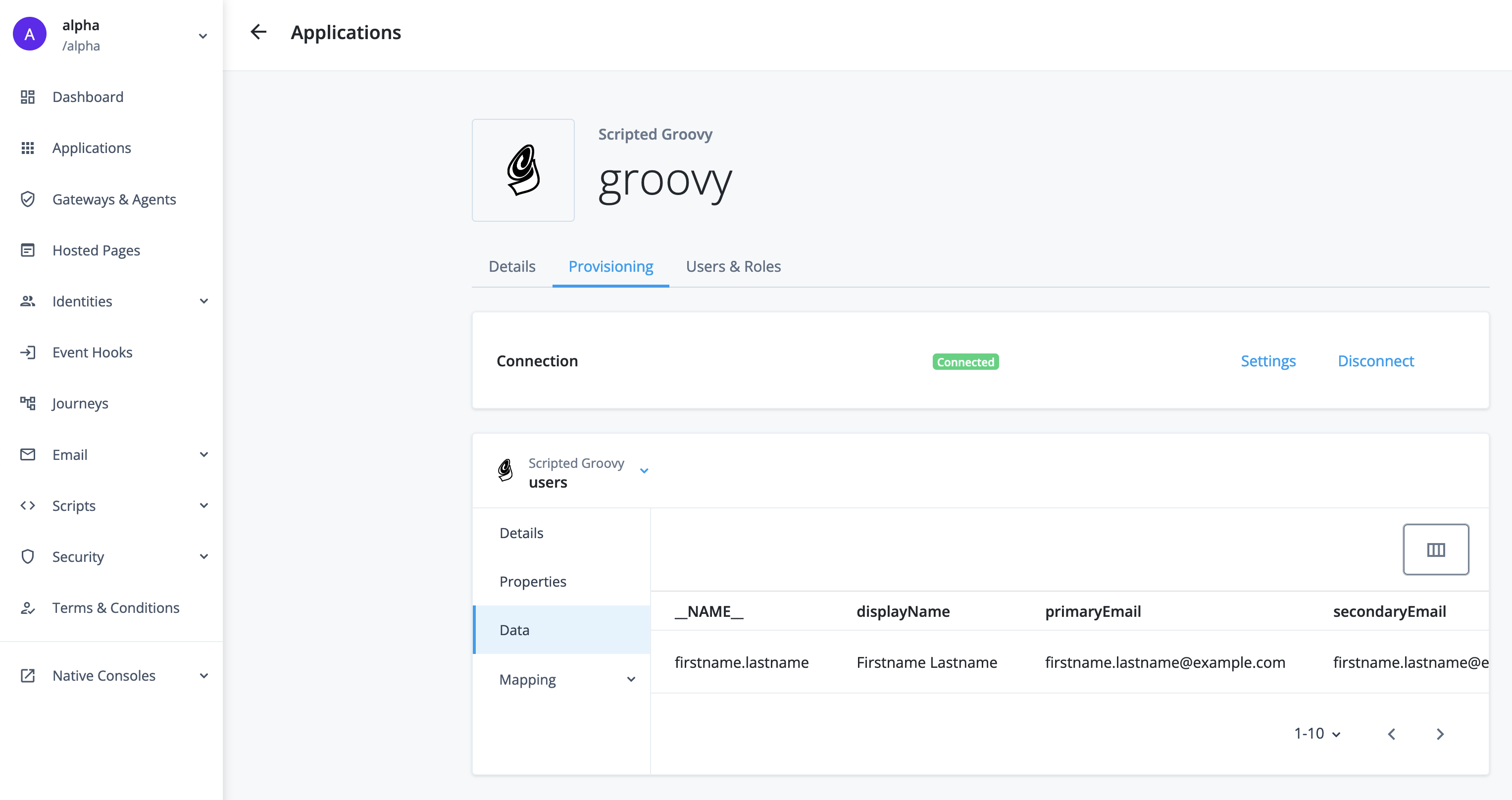
To respond with multiple resources, you need to call the handler
method for each resource to be included in the search operation result.
The source data should be available for the search script as an iterable
data type, such as
java.util.ArrayList.
Then, you can loop over the list and call the handler method for each
object in the list.
For example, if your data comes in a JSON (file), you can parse it with Groovy and iterate over the result:
SearchScript.groovy
import groovy.json.JsonSlurper
def jsonSlurper = new JsonSlurper()
def json = new File('/var/lib/rcs/users.json')
def resources = json.exists() ? (jsonSlurper.parse(json)).Resources : []
resources.each { resource ->
handler {
uid resource.id
id resource.userName
attribute 'active', !!resource.active
attribute 'displayName', resource.displayName
attribute 'givenName', resource.name.givenName // 1
attribute 'middleName', resource.name.middleName
attribute 'familyName', resource.name.familyName
attribute 'primaryEmail', (resource.emails.find { resource.primary })?.value // 2
attribute 'secondaryEmail', (resource.emails.find { !resource.primary })?.value
}
}
-
Individual value from the user’s name object can be used to populate a field.
-
Array methods can be used to obtain an individual object from a list.
The example data here is a SCIM Query Resources response from the
/Usersendpoint, in which case a list of users is saved under the “Resources” key.
Now, the result of the search operation will be populated dynamically from the provided data.
For example:
{
"result": [
{
"_id": "2819c223-7f76-453a-919d-413861904646",
"__NAME__": "bjensen",
"displayName": "Ms. Barbara J Jensen III",
"primaryEmail": "bjensen@example.com",
"middleName": "Jane",
"active": false,
"givenName": "Barbara",
"familyName": "Jensen"
},
[ . . . ]
],
"resultCount": 19,
"pagedResultsCookie": null,
"totalPagedResultsPolicy": "NONE",
"totalPagedResults": -1,
"remainingPagedResults": -1
}
Each object class that you expect to be searchable will need to be
handled within your search script. Different object classes can be
associated with different data sources, have different attributes, or
otherwise require different processing. This means, you will likely need
to organize your code so that the result set for each object class is
treated uniquely, using conditional logic. You can determine which
object class data has been requested from the search operation by
inspecting the objectClass binding and base your conditional logic on
its content.
If a search operation request is not supported in your script—for example, if an object class is defined in the connector schema, but is not handled in the script—the request should result in UnsupportedOperationException with an informative message.
For the reasons discussed in the Debugging Scripts > Try and Catch chapter, you should also handle any errors in your search script and respond with custom error messages.
For example:
SearchScript.groovy
import groovy.json.JsonSlurper
try {
def jsonSlurper = new JsonSlurper()
switch (objectClass.objectClassValue) {
case 'users':
def json = new File('/var/lib/rcs/users.json')
def resources = json.exists() ? (jsonSlurper.parse(json)).Resources : []
resources.each { resource ->
handler {
uid resource.id
id resource.userName
attribute 'active', !!resource.active
attribute 'displayName', resource.displayName
attribute 'givenName', resource.name.givenName
attribute 'middleName', resource.name.middleName
attribute 'familyName', resource.name.familyName
attribute 'primaryEmail', (resource.emails.find { resource.primary })?.value
attribute 'secondaryEmail', (resource.emails.find { !resource.primary })?.value
}
}
break
case 'groups':
def json = new File('/var/lib/rcs/groups.json')
def resources = json.exists() ? (jsonSlurper.parse(json)).Resources : []
resources.each { resource ->
handler {
uid resource.id
attribute 'displayName', resource.displayName
attribute 'members', resource.members
attribute 'schemas', resource.schemas
}
}
break
default:
throw new UnsupportedOperationException(operation.name() + ' operation of type ' + objectClass.getObjectClassValue() + ' is not supported.')
}
} catch (UnsupportedOperationException e) {
/**
* Preserve and re-throw the custom exception on unrecognized object class.
*/
throw e
} catch (e) {
log.error 'EXCEPTION: ' + e.message
throw new UnsupportedOperationException('Error occurred during ' + operation + ' operation')
}
As demonstrated in the example code, an object class can be identified by its type found with the
objectClass.getObjectClassValue()method.In addition, ObjectClass class has some predefined types and corresponding constants that you could use in your code.
For example:
[ . . . ] switch (objectClass.getObjectClassValue()) { case ObjectClass.ACCOUNT_NAME: [ . . . ][ . . . ] switch (objectClass) { case ObjectClass.ACCOUNT: [ . . . ]
##Scripted Groovy Connector (Toolkit) > Search Script > Filtering Results
When invoking a search operation via IDM’s APIs, you MUST provide search criteria using one of the following:
-
Resource ID
-
Query Definition
Search arguments, such as a resource ID or an attribute value, will be
used to populate the filter binding, from which you will be able to
extract the search parameters. For example, you can use use the query
binding, which is a closure you can call to obtain a map of the search
parameters.
##Scripted Groovy Connector (Toolkit) > Search Script > Filtering Results > Read by Resource ID
For a single specific resource, you can specify its ID as a URL path argument:
-
/openidm/system/<connection-name>/<object-class>/<ID>(in a CREST Read request) -
openidm.read('system/<connection-name>/<object-class>/<ID>')(in an openidm.read(resourceName, params, fields) function call)
For example:
IDM admin UI Browser Console
(async function () {
var data = await $.ajax('/openidm/system/groovy/users/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx');
console.log(JSON.stringify(data, null, 4));
}());
A response from a successful read request made via IDM’s APIs will be a single object JSON populated with data from the first resource handled by your search script.
For example:
{
"_id": "2819c223-7f76-453a-919d-413861904646",
"__NAME__": "bjensen",
"displayName": "Ms. Barbara J Jensen III",
"primaryEmail": "bjensen@example.com",
"middleName": "Jane",
"active": false,
"givenName": "Barbara",
"familyName": "Jensen"
}
In order for it to match the specified ID, your script needs to implement filtering logic.
-
Using the
querybinding.The
querybinding is a closure which returns a map of search parameters from thefilterbinding. In a search script, the passed in ID condition will appear as an entry in the map returned by thequeryclosure.For example:
SearchScript.groovyprintln query() [ . . . ]
RCS logs[not:false, operation:EQUALS, left:__UID__, right:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx]
The
UIDparameter is a part of convention that includes a number of ICF special attributes that begin and end with the double underscore. ICF’sUIDname references a resource unique identifier.In the Query Definition chapter, it will be explained in details how the map returned by a
query()call can be used for filtering data in response to either a read or a query request. -
Using the
filterbinding.You can use the FrameworkUtil.getUidIfGetOperation(Filter filter) method to extract the passed in ID and apply it in the following way:
SearchScript.groovyimport groovy.json.JsonSlurper import org.identityconnectors.framework.common.FrameworkUtil def jsonSlurper = new JsonSlurper() [ . . . ] def json = new File('/var/lib/rcs/users.json') def resources = json.exists() ? (jsonSlurper.parse(json)).Resources : [] def uuid = FrameworkUtil.getUidIfGetOperation(filter) if (uuid) { // GET the matching resource. def resource = resources.find { it.id == uuid.uidValue } if (resource) { handler { uid resource.id id resource.userName attribute 'active', !!resource.active attribute 'displayName', resource.displayName attribute 'givenName', resource.name.givenName attribute 'middleName', resource.name.middleName attribute 'familyName', resource.name.familyName attribute 'primaryEmail', (resource.emails.find { it.primary })?.value attribute 'secondaryEmail', (resource.emails.find { !it.primary })?.value } } } [ . . . ]Requesting a non-existing ID will result in no
handlercall; hence, the response will contain a “Not Found” error:{ "code": 404, "reason": "Not Found", "message": "Object xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx not found on system/groovy/users" }Requesting an existing ID will result in a
handlercall, and the response from IDM’s APIs will be a single object JSON with the matching value in the “_id” field.For example:
IDM admin UI Browser Console(async function () { var data = await $.ajax('/openidm/system/groovy/users/2819c223-7f76-453a-919d-413861904646'); console.log(JSON.stringify(data, null, 4)); }());{ "_id": "2819c223-7f76-453a-919d-413861904646", "__NAME__": "bjensen", "displayName": "Ms. Barbara J Jensen III", "primaryEmail": "bjensen@example.com", "middleName": "Jane", "active": false, "givenName": "Barbara", "familyName": "Jensen" }
##Scripted Groovy Connector (Toolkit) > Search Script > Filtering Results > Query Definition
To request a list of resources from a search operation, you can include
a _queryFilter argument populated with a
query
definition. In your search script, the query definition can be
evaluated as true to include a resource or as false to exclude it
from the search result.
In a query request sent via IDM’s REST, a query definition becomes a part of the URL query:
/openidm/system/<connection-name>/<object-class>?_queryFilter=<query-definition>
In an IDM script, the query definition will be included in the openidm.query(resourceName, params, fields) params:
openidm.query('system/<connection-name>/<object-class>', {
_queryFilter: '<query-definition>'
});
The query definition will be used to set values of the filter and
query bindings in your search script.
In the simplest scenario, with _queryFilter=true (or
_queryFilter: 'true'), both the filter object and the value returned
by the query closure are null. This indicates (to the script) that
all resources for the requested object class should satisfy the search
criteria, and no filtering should be applied.
With
_queryFilter=false(or_queryFilter: 'false'), the search script would not run at all, and an empty result set would be included in the response from IDM’s APIs.
To build a functional query definition, you need to follow conventions
described in
Define
and call data queries and CREST
Query
docs.
Both documents describe generic IDM search operations; not everything described there can be used within RCS search scripts.
For example, you might come across references to
_queryExpressionargument, which might behave similarly toqueryFilteron RCS, but_queryExpressionis not officially supported in RCS context.
Correctly built and accepted by IDM’s APIs query definition will be used
to populate the filter and the query bindings with the passed in
search criteria:
-
Methods of a filter object can be used to produce different representations of the search parameters, such as an SQL string or a map, by accepting custom implementations of FilterVisitor.
The scripted example of MySQL connector, which could be found in Samples provided with IDM or in the General Access Connectors repository, demonstrates how filter criteria can be converted into an SQL statement.
-
The
querybinding is a Closure, which returns a map of search parameters from thefilterobject.The map returned by a
query()call has predictable structure and can be used for generating conditional logic for filtering the result of a search operation.This makes calling the
queryclosure an easy and the preferred way of extracting the search parameters if you don’t have a specific FilterVisitor for your source of data.For example:
Query definition?_queryFilter=(primaryEmail pr) and active eq true
SearchScript.groovyprintln query().inspect()
RCS logs[rcs] ['operation':'AND', 'left':['operation':'PRESENT', 'not':false, 'left':'primaryEmail'], 'right':['not':false, 'operation':'EQUALS', 'left':'active', 'right':'true']]
Currently, the following expressions and operators are accepted in a query definition:
| Operation | Expression | Example of _queryFilter |
query() |
|---|---|---|---|
presence (of property) |
<pointer> |
givenName pr |
[‘operation’:‘PRESENT’, ‘not’:false, ‘left’:‘givenName’] |
contains |
<pointer> |
givenName co “bar” |
[‘not’:false, ‘operation’:‘CONTAINS’, ‘left’:‘givenName’, ‘right’:‘bar’] |
equal to |
<pointer> |
givenName eq “Barbara” |
[‘not’:false, ‘operation’:‘EQUALS’, ‘left’:‘givenName’, ‘right’:‘Barbara’] |
greater than |
<pointer> |
givenName gt “Barbara” |
[‘not’:false, ‘operation’:‘GREATERTHAN’, ‘left’:‘givenName’, ‘right’:‘Barbara’] |
greater than or equal to |
<pointer> |
givenName ge “Barbara” |
[‘not’:false, ‘operation’:‘GREATERTHANOREQUAL’, ‘left’:‘givenName’, ‘right’:‘Barbara’] |
less than |
<pointer> |
givenName lt “B” |
[‘not’:false, ‘operation’:‘LESSTHAN’, ‘left’:‘givenName’, ‘right’:‘B’] |
less than or equal to |
<pointer> |
givenName le “Barbara” |
[‘not’:false, ‘operation’:‘LESSTHANOREQUAL’, ‘left’:‘givenName’, ‘right’:‘Barbara’] |
starts with |
<pointer> |
givenName sw “Bar” |
[‘not’:false, ‘operation’:‘STARTSWITH’, ‘left’:‘givenName’, ‘right’:‘Bar’] |
ends with |
<pointer> |
givenName ew “ara” |
[‘not’:false, ‘operation’:‘ENDSWITH’, ‘left’:‘givenName’, ‘right’:‘ara’] |
AND |
<expression> |
givenName eq “Barbara” and familyName eq “Jensen” |
[‘operation’:‘AND’, ‘left’:[‘not’:false, ‘operation’:‘EQUALS’, ‘left’:‘givenName’, ‘right’:‘Barbara’], ‘right’:[‘not’:false, ‘operation’:‘EQUALS’, ‘left’:‘familyName’, ‘right’:‘Jensen’]] |
OR |
<expression> |
givenName eq “Barbara” or familyName eq “Jensen” |
[‘operation’:‘OR’, ‘left’:[‘not’:false, ‘operation’:‘EQUALS’, ‘left’:‘givenName’, ‘right’:‘Barbara’], ‘right’:[‘not’:false, ‘operation’:‘EQUALS’, ‘left’:‘familyName’, ‘right’:‘Jensen’]] |
NOT |
|
!(givenName eq “Barbara”) |
[‘not’:true, ‘operation’:‘EQUALS’, ‘left’:‘givenName’, ‘right’:‘Barbara’] |
Literal |
|
true |
null |
Each query expression represents a single operation. Individual query
expressions can be used in an AND/OR clause and grouped with
parenthesis.
In a complex query definition, the left and right parts of an operation may consist of nested maps, where each map introduces a single condition.
For example:
?_queryFilter=(givenName eq "Barbara" or givenName eq "Jane") and familyName eq "Jensen"
The result of a query() call with extra whitespace for readability:
[
'operation':'AND',
'left':[
'operation':'OR',
'left':[
'not':false,
'operation':'EQUALS',
'left':'givenName',
'right':'Barbara'
],
'right':[
'not':false,
'operation':'EQUALS',
'left':'givenName',
'right':'Jane'
]
],
'right':[
'not':false,
'operation':'EQUALS',
'left':'familyName',
'right':'Jensen'
]
]
You can use this standard representation of the search parameters to dynamically generate conditional logic for filtering the result, which is demonstrated in the Example Search Script > Flat Representation of Data chapter.
Your query definition will be validated before the search script is executed and independently for each expression. If validation fails, you might receive the following errors:
-
Except when checked for presence, unrecognized pointers (that is, attribute references unaccounted in the connector schema) will result in an error, even if you checked for presence first in your query definition.
For example:
?_queryFilter=firstName pr and firstName eq "Barbara"{"code":400,"reason":"Bad Request","message":"Attribute firstName does not exist as part of ObjectClass: users"} -
If you try to use an unrecognized expression or an unsupported operator, you will receive a 4xx error.
For example:
{"code":400,"reason":"Bad Request","message":"ExtendedMatchFilter is not supported"}{"code":404,"reason":"Not Found","message":"ContainsAllValuesFilter transformation is not supported"}{"code":404,"reason":"Not Found","message":"Complex filter not supported"} -
If you use unrecognized arguments starting with an underscore, you will receive a 400 error.
For example:
{"code":400,"reason":"Bad Request","message":"Unrecognized request parameter '_query'"}Any additional arguments in the URL query that do not start with an underscore will be ignored and not present in the search script context.
##Scripted Groovy Connector (Toolkit) > Search Script > Paging and Sorting
The Define and call data queries document describes how your search script SHOULD react to additional sorting and paging arguments provided in the request. You can only use paging arguments along with a query; they will not be accepted (nor needed) when processing a read request.
To implement reliable paging, you need to make sure no valid resources are skipped as you iterate through the pages. One common way to achieve that is to sort the result on a stable attribute, and to use a value-based paging strategy that refers to the last value for the given page from that attribute in order to establish a consistent reference for the next page.
To request paging, you need to specify page size.
-
##Page Size
The
_pageSizeargument specifies the number of resources each page (that is, a single result of a search operation) should be limited to:&_pageSize=<positive-integer>(in a CREST Query)_pageSize: <positive-integer>(in openidm.query(resourceName, params, fields) params)+ In a search script context, this parameter becomes available as the
options.pageSizebinding. Presence of a positive value in theoptions.pageSizeparameter indicates that paging is requested. -
##Sorting
You might be able to rely on the order your resources are received from the target backend, but sorting your resources explicitly in the script will ensure consistent results.
A request for a search operation may contain sorting criteria in a
_sortKeysargument:&_sortKeys=<pointer>,<pointer> . . . ` (in a CREST Query)`_sortKeys: [' <pointer>', '<pointer>' . . . ] (in openidm.query(resourceName, params, fields) params)+ By default, the order in which each sort key is to be applied is ascending. You can change it by prefixing a pointer with a
-(minus) sign in your request.+ For example:
+
&_sortKeys=-NAME+ In the search script context, the sorting criteria becomes available as the
options.sortKeysbinding, which is an array of the SortKey class instances.+ The sorting information might not be provided in a request, or it could reference non-unique identifiers making sorting by them inconsistent and unreliable. Therefore, if paging is requested, you should always do the last sorting by the object class unique identifier, its
_idproperty; and accordingly, add the correspondingSortKeyto the array.+ For example:
+
SearchScript.groovy+
[ . . . ] def sortKeys = options.sortKeys if (!sortKeys || sortKeys?.last().field != '_UID_') { sortKeys += new SortKey('__UID__', true) } [ . . . ]+
If an
_idargument were included in a request, it would be translated into an ICF-namedUIDparameter in the search script context. Hence, to treat all attribute references consistently, theUIDname is used as the SortKey field in this last example.+
The
options.sortKeysbinding is not present on read requests.+ You can use accessors of the SortKey class to retrieve the attribute name and the direction by which you need to sort your result.
+ For example:
+
SearchScript.groovy+
/** * Apply sort keys in reverse order, so that sorting by multiple keys is possible. */ sortKeys.reverse().each { sortKey -> resources = resources.sort { a, b -> def valueA = a[sortKey.field].toString() def valueB = b[sortKey.field].toString() if (sortKey.isAscendingOrder) { valueA.compareToIgnoreCase(valueB) } else { valueB.compareToIgnoreCase(valueA) } } } -
##Tracking Position in Paged Results
If the client has already received some paged result, it will need to indicate where to start next page in its requests for a paged search operation.
Either
_pagedResultsCookieor_pagedResultsOffsetargument can be used for this purpose.Currently, both arguments can be provided simultaneously in IDM scripts; hence, you script should make application of these parameters mutually exclusive.
Note that for reconciliation IDM only uses
_pagedResultsCookie; so, if you are building a connector specifically to work with reconciliation, that option should be the focus of the implementation. **_pagedResultsCookie+ If paging is requested, and your script is not responding with the last page, you should inform the client about the last handled resource. This is done by including the last resource unique identifier as the value of
pagedResultsCookieproperty in an instance of the SearchResult class, and returning the instance from the script.+ Having received the reference to the last resource from a search operation, the client can include it in its next request—to indicate where the next page needs to start. In order to avoid any translation errors in this exchange, the value of the unique identifier should be base-64 and URL-encoded.
+ For example, where
remainingPagedResultsis a calculated value based on tracking the last handled resource:+
SearchScript.groovy+
import org.identityconnectors.framework.common.objects.SearchResult def pagedResultsCookie [ . . . ] if (remainingPagedResults > 0) { pagedResultsCookie = resources?.last().uid.bytes.encodeBase64Url().toString() } [ . . . ] new SearchResult( pagedResultsCookie, -1 )+
IDM does not support SearchResult.CountPolicy for
/systemendpoints; hence, you cannot leverage the SearchResult(java.lang.String pagedResultsCookie, SearchResult.CountPolicy totalPagedResultsPolicy, int totalPagedResults, int remainingPagedResults) constructor. In effect, you can only respond withpagedResultsCookiefrom your scripted connector.+ The client will receive this information as a part of the response from the search operation request.
+ For example:
+
{ "result": [ [ . . . ] ], "resultCount": 8, "pagedResultsCookie": "MjgxOWMyMjMtN2Y3Ni00NTNhLTkxOWQtNDEzODYxOTA0NjQ2", "totalPagedResultsPolicy": "NONE", "totalPagedResults": -1, "remainingPagedResults": -1 }+ If the client wants to proceed with the next page, it can include this last resource reference in its next request as a
_pagedResultsCookieargument:-
&_pagedResultsCookie=<paged-results-cookie>(in a CREST Query) -
_pagedResultsCookie: <paged-results-cookie>(in openidm.query(resourceName, params, fields) params)The search script will receive this value in the
options.pagedResultsCookieparameter, and will need to decode it to determine the last ID position in the source data to start the next page from.For example:
SearchScript.groovy[ . . . ] lastHandledIndex = resources.findIndexOf { resource -> resource.uid == new String(options.pagedResultsCookie.decodeBase64Url()) } [ . . . ]When the last page is returned,
pagedResultsCookiein the SearchResult instance returned from the script should not be assigned any value, making the “pagedResultsCookie” field in the search operation response populated withnull, which will conclude the paging cycle. **_pagedResultsOffset+ When a positive
_pagedResultsOffsetvalue is received, the search script is to discard the number of resources indicated by the argument value from the beginning of the search operation result.+ For example:
+
SearchScript.groovy+
[ . . . ] if (options.pagedResultsOffset) { resources = resources.drop options.pagedResultsOffset } [ . . . ]+ In this case,
pagedResultsCookiestill needs to be sent back to the client to make it aware of incomplete paged result and of the position where the last page ended; thus, making it an option for the client to start paging from this position using the_pagedResultsCookieargument.
-
The
Example
Search Script chapter demonstrates applying sorting and paging
parameters in a Groovy connector. In the example scripts, look for the
code and comments associated with options.pageSize,
options.sortKeys, options.pagedResultsCookie, and
options.pagedResultsOffset to see the implementation details.
##Scripted Groovy Connector (Toolkit) > Search Script > Attributes to Get
By default, all handled attributes that are defined in the connector
schema will be included in the result of a search operation, except the
ones that are marked with the NOT_RETURNED_BY_DEFAULT
flag.
In a request for search operation, either read or query, you can specify
what attributes should be included in the response by providing a
comma-separated list of attribute names in a _fields argument:
-
&_fields=pointer[,pointer . . . ](in a CREST Query) -
[ 'pointer', . . . ](in openidm.query(resourceName, params, fields) fields, which is the third and last argument of this method)
Attributes not matching the populated _fields value will be
automatically excluded from the search operation response with one
exception: a response from IDM’s REST will always include the _id
attribute.
For example:
?_queryFilter=true&_fields=NAME
{
"result": [
{
"_id": "2819c223-7f76-453a-919d-413861904646",
"__NAME__": "bjensen"
},
[ . . . ]
],
"resultCount": 19,
"pagedResultsCookie": null,
"totalPagedResultsPolicy": "NONE",
"totalPagedResults": -1,
"remainingPagedResults": -1
}
To reference all attributes that are included in a response by default,
you can use a * (asterisk) wildcard.
Then, the _fields argument can be used for including attributes marked
with the NOT_RETURNED_BY_DEFAULT
flag.
For example:
?_queryFilter=true&_fields=*,secondaryEmail
{
"result": [
{
"_id": "2819c223-7f76-453a-919d-413861904646",
"__NAME__": "bjensen",
"displayName": "Ms. Barbara J Jensen III",
"primaryEmail": "bjensen@example.com",
"middleName": "Jane",
"active": false,
"givenName": "Barbara",
"familyName": "Jensen",
"secondaryEmail": "babs@jensen.org"
},
[ . . . ]
],
"resultCount": 19,
"pagedResultsCookie": null,
"totalPagedResultsPolicy": "NONE",
"totalPagedResults": -1,
"remainingPagedResults": -1
}
In the search script context, the list of requested attributes will be
available as the options.attributesToGet parameter, which is an array
of Strings.
For example:
/openidm/system/groovy/users/2819c223-7f76-453a-919d-413861904646?_fields=NAME
SearchScript.groovy
println options.attributesToGet [ . . . ]
RCS logs
[__NAME__]
If you have an expensive attribute to process, you might want to consult this list and only process the fields that have been requested.
If the _fields argument is not included in the request or is empty,
all attributes that are included by default will be present in the
array.
For example:
/openidm/system/groovy/users/2819c223-7f76-453a-919d-413861904646?_fields=
RCS logs
['displayName', 'givenName', 'familyName', 'active', 'middleName', '__NAME__', 'primaryEmail']
Currently, setting the “enableAttributesToGetSearchResultsHandler” key to
falsein a scripted Groovy connector configuration does not change the described in this chapter default behavior driven by the_fieldsargument.{ "connectorRef": { "connectorHostRef": "rcs", "bundleVersion": "1.5.20.15", "bundleName": "org.forgerock.openicf.connectors.groovy-connector", "connectorName": "org.forgerock.openicf.connectors.groovy.ScriptedConnector" }, "resultsHandlerConfig": { "enableAttributesToGetSearchResultsHandler": true, [ . . . ] }, [ . . . ] }
##Scripted Groovy Connector (Toolkit) > Search Script > Example Search Script
======= ##Scripted Groovy Connector (Toolkit) > Search Script > Example Search Script > Flat Representation of Data
The example below demonstrates how some of the conventions described in
Define
and call data queries and
ForgeRock
Common REST > Query docs can be translated into a script.
The example script handles requests for two object classes outlined in the Example Schema Script > Flat Representation of Data chapter.
In order to apply search criteria dynamically and universally, the following considerations have been addressed in the example script:
-
Different query definitions will need to be handled in the same script.
If you don’t have a FilterVisitor for your source of data, you will need to build a condition generator, which will consume the dynamic input returned by a
query()call and use it to produce filtering logic that can be applied to your data source. -
A connector may handle requests for multiple object classes.
The ICF framework conventionally uses
UIDandNAMEas a resource unique identifier and its user-friendly identifier in the search parameters delivered to a search script. In the closure passed into thehandlermethod, the respective attributes are represented asuidandidfields.In a remote system the corresponding identifiers could be found under different properties for different object classes. Thus, it might be beneficial to transform all sources’ data to match ICF conventions, map the ICF names received in the request to the fields existing the converted dataset, and use this map as a reference in your filtering and handling logic that can be shared between different object classes.
For example:
/** * Map ICF ID names (used in the filter) to ICF ID fields (used in handler). */ def queryFieldMap = [ '__UID__': 'uid', '__NAME__': 'id' ] [ . . . ] /** * Get a resource data in the format matching the object class schema. * * @param resource org.apache.groovy.json.internal.LazyMap * Represents a resource object. * @return java.util.LinkedHashMap * Represents a resource. */ def getResourceData = { resource -> [ uid: resource.id, id: resource.userName, [ . . . ] ] }The unique identifier is returned as the “_id” key in a search operation result. Whether you use its value in the path of a read request or as an
_idargument in a query request, in the map returned by aquery()call the argument will be converted into ICF’sUIDparameter.For example:
/openidm/system/groovy/users/2819c223-7f76-453a-919d-413861904646RCS logs['not':false, 'operation':'EQUALS', 'left':'__UID__', 'right':'2819c223-7f76-453a-919d-413861904646']
-
In order for search arguments to be accepted by the APIs, the corresponding attribute needs to be defined as a primitive type in the connector’s schema.
If you attempt to search against an Object attribute using a String value in a query definition, you may receive an error:
{"code":400,"reason":"Bad Request","message":"java.lang.String to java.util.Map"}In the Example Schema > Flat Representation of Data script, properties of the complex attributes have been defined as individual attributes in the
usersobject class. The search script has to accommodate this schema by obtaining corresponding individual properties from theusersdata.This also presents an opportunity to align the search operation result with any validation policies implemented in the target system.
Below find an example search script for a simple Groovy connector that gets data from a JSON file, but similarly could handle any other list of objects that can be converted into an array of maps. The script implements all the functionality that have been discussed in this chapter.
The example script serves illustration purposes; modify and optimize it for your use.
SearchScript.groovy
/**
* DISCLAIMER
* The sample code described herein is provided on an "as is" basis, without warranty of any kind,
* to the fullest extent permitted by law. ForgeRock does not warrant or guarantee the individual success
* developers may have in implementing the sample code on their development platforms or in production
* configurations. ForgeRock does not warrant, guarantee or make any representations regarding the use, results
* of use, accuracy, timeliness or completeness of any data or information relating to the sample code.
* ForgeRock disclaims all warranties, expressed or implied, and in particular, disclaims all warranties of
* merchantability, and warranties related to the code, or any service or software related thereto.
* ForgeRock shall not be liable for any direct, indirect or consequential damages or costs of any type arising
* out of any action taken by you or others related to the sample code.
*/
/**
* @file Provide an example search script for use with Groovy Toolkit connectors.
* @author Konstantin.Lapine@forgerock.com
* @version 0.1.0
* Defined variables:
* filter org.identityconnectors.framework.common.objects.filter.Filter
* The search parameters.
* query groovy.lang.Closure
* Returns a map of search parameters from the filter object.
* options org.identityconnectors.framework.common.objects.OperationOptions
* Additional search parameters.
* objectClass org.identityconnectors.framework.common.objects.ObjectClass
* Represents the requested object class.
* @see {@link https://backstage.forgerock.com/docs/openicf/latest/_attachments/apidocs/org/identityconnectors/framework/common/objects/ObjectClass.html}
* @see {@link https://backstage.forgerock.com/docs/openicf/latest/_attachments/apidocs/org/identityconnectors/framework/common/objects/OperationOptions.html}
* handler groovy.lang.Closure
* Adds a resource to the search operation result.
* operation org.forgerock.openicf.connectors.groovy.OperationType
* The SEARCH operation type.
* configuration org.forgerock.openicf.connectors.groovy.ScriptedConfiguration
The connector configuration properties.
* @see {@link https://backstage.forgerock.com/docs/openicf/latest/connector-reference/groovy.html#groovy-connector-configuration}
* log org.identityconnectors.common.logging.Log
* Logging facility.
* @see {@link https://backstage.forgerock.com/docs/openicf/latest/_attachments/apidocs/org/identityconnectors/common/logging/Log.html}
* Returns org.identityconnectors.framework.common.objects.SearchResult
* @see {@link https://backstage.forgerock.com/docs/openicf/latest/_attachments/apidocs/org/identityconnectors/framework/common/objects/SearchResult.html}
*
*/
import org.identityconnectors.framework.common.objects.SearchResult
import groovy.json.JsonSlurper
try {
/**
* Identify the ICF operation in RCS logs.
*/
log.info 'Script: ' + configuration.scriptRoots + '/' + configuration.searchScriptFileName + ' Operation: ' + operation
def jsonSlurper = new JsonSlurper()
/**
* Map ICF ID names (used in the filter) to ICF ID fields (used in handler),
* for automated lookup.
*/
def queryFieldMap = [
'__UID__': 'uid',
'__NAME__': 'id'
]
/**
* Define defaults for paging.
*/
def pagedResultsCookie
def remainingPagedResults
def lastHandledIndex = -1
def totalPagedResults
/**
* Parse the search criteria if it has been provided,
* and generate a condition template to be evaluated against a resource.
*
* @return java.lang.String | null
*/
def getConditionTemplate = {
/**
* Create a condition template to dynamically evaluate against a resource data.
* @param query java.util.LinkedHashMap
* Represents a query operation,
* where left and right parts of the condition could be other query operation maps.
* @param fieldMap java.util.LinkedHashMap
* Contains query parameters mapped to an object class-specific attributes.
* @return java.lang.String
* Contains the condition template.
*/
def conditionGenerator = { query, fieldMap=[:] ->
/**
* Parse each query operation individually
* and combine them in AND/OR clause(s) if requested.
*/
if (query.operation == 'AND' || query.operation == 'OR') {
def operation = '&&'
if (query.operation == 'OR') {
operation = '||'
}
return '(' + call(query.right, fieldMap) + ' ' + operation + ' ' + call(query.left, fieldMap) + ')'
} else {
def objectClassType = objectClass.objectClassValue
def argumentValue = query.right
def not = query.not ? '!' : ''
def template
def attributeName = query.left
if (fieldMap[attributeName]) {
attributeName = fieldMap[attributeName]
}
attributeName = 'resource.' + attributeName
/**
* Ensure the resource attribute is evaluated to a string value
* for string comparisons with the search arguments.
*/
attributeTemplate = attributeName + '.toString()'
switch (query.operation) {
case 'PRESENT':
template = "$not(${attributeName})"
break
case 'EQUALS':
template = "$attributeName && $not(${attributeTemplate}.equalsIgnoreCase('$argumentValue'))"
/**
* For case-sensitive comparison, you can use the equals(Object object) method or the equality operator.
* @example
* template = "$attributeName && $not($attributeTemplate == '$argumentValue')"
*/
break
case 'GREATERTHAN':
template = "$attributeName && $not(${attributeTemplate}.compareToIgnoreCase('$argumentValue') > 0)"
break
case 'GREATERTHANOREQUAL':
template = "$attributeName && $not(${attributeTemplate}.compareToIgnoreCase('$argumentValue') >= 0)"
break
case 'LESSTHAN':
template = "$attributeName && $not(${attributeTemplate}.compareToIgnoreCase('$argumentValue') < 0)"
break
case 'LESSTHANOREQUAL':
template = "$attributeName && $not(${attributeTemplate}.compareToIgnoreCase('$argumentValue') <= 0)"
break
case 'CONTAINS':
template = "$attributeName && $not(${attributeTemplate}.containsIgnoreCase('$argumentValue'))"
break
case 'ENDSWITH':
template = "$attributeName && $not(${attributeTemplate}.endsWithIgnoreCase('$argumentValue'))"
/**
* Alternatively, you could use a regular expression.
* @example
* template = "$attributeName && $not(($attributeTemplate =~ /\\w*$argumentValue\$/).size())"
*/
break
case 'STARTSWITH':
template = "$attributeName && $not(${attributeTemplate}.startsWithIgnoreCase('$argumentValue'))"
}
return template
}
}
if (query()) {
/**
* Parse the query data and get back a condition template
* for evaluating against a resource in GroovyShell.
*/
conditionTemplate = conditionGenerator query(), queryFieldMap
}
}
/**
* Transform resources to match the object class schema,
* and optionally filter resources based on the search parameters received in the request.
*
* @param resources java.util.ArrayList
* A list of org.apache.groovy.json.internal.LazyMap instances,
* each representing a resource object for an object class.
* @param getResourceData groovy.lang.Closure
* Returns a single resource data in the format matching the object class schema.
* @return java.util.ArrayList
* Filtered list of org.apache.groovy.json.internal.LazyMap instances.
*/
def filterResources = { resources, getResourceData ->
def conditionTemplate = getConditionTemplate()
if (conditionTemplate) {
resources = resources.collectMany { resource ->
def resourceData = getResourceData(resource)
/**
* Use Groovy shell for evaluating the condition template with a placeholder for dynamically supplied data.
*/
def groovyShellBinding = new Binding()
def groovyShell = new GroovyShell(groovyShellBinding)
/**
* Provide dynamic, resource-specific content for the conditional template.
*/
groovyShellBinding.setVariable 'resource', resourceData
/**
* Exclude resources that do not meet search criteria from the search result.
*/
groovyShell.evaluate(conditionTemplate) ? [resourceData] : []
}
} else {
resources = resources.collect { resource ->
getResourceData resource
}
}
}
/**
* (Re)define sort keys if sorting and/or paging are requested.
*
* @return java.util.ArrayList
* of org.identityconnectors.framework.common.objects.SortKey instances.
*/
def getSortKeys = {
def sortKeys = options.sortKeys
/**
* Define default sorting by the unique identifier to ensure reliable paging.
* @see {@link https://backstage.forgerock.com/docs/openicf/latest/_attachments/apidocs/org/identityconnectors/framework/common/objects/SortKey.html}
* @see {@link https://backstage.forgerock.com/docs/openicf/latest/_attachments/apidocs/org/identityconnectors/framework/common/objects/Uid.html}
*/
if (!sortKeys || sortKeys?.last().field != '_UID_') {
sortKeys += new SortKey('__UID__', true)
}
/**
* Replace ICF names present in sort keys with ICF ID fields used in resource data.
*/
sortKeys.collect { sortKey ->
def field = sortKey.field
if (queryFieldMap[field]) {
field = queryFieldMap[field]
}
new SortKey(field, sortKey.isAscendingOrder)
}
}
/**
* Sort an object class data if sorting and/or paging are requested.
* Apply the sort keys in reverse order to allow fo sorting by multiple keys.
*
* @param resources java.util.ArrayList
* A list of org.apache.groovy.json.internal.LazyMap instances,
* each representing a resource object.
* @return java.util.ArrayList
* Sorted list of the resources.
*/
def sortResources = { resources ->
def sortKeys = getSortKeys()
sortKeys.reverse().each { sortKey ->
resources = resources.sort { a, b ->
def valueA = a[sortKey.field].toString()
def valueB = b[sortKey.field].toString()
if (sortKey.isAscendingOrder) {
valueA.compareToIgnoreCase(valueB)
} else {
valueB.compareToIgnoreCase(valueA)
}
}
}
resources
}
/**
* Create a page for an object class data.
* Set pagedResultsCookie.
*
* @param resources java.util.ArrayList
* A list of org.apache.groovy.json.internal.LazyMap instances,
* each representing a resource object.
* @return java.util.ArrayList
* Paged list of the resources.
*/
def pageResources = { resources ->
/**
* Skip resources that have been included in previous pages or explicitly excluded.
*/
if (options.pagedResultsCookie) {
/**
* Get position of the last handled resource in the sorted result.
*/
lastHandledIndex = resources.findIndexOf { resource ->
resource.uid == new String(options.pagedResultsCookie.decodeBase64Url())
}
/**
* Discard already handled resources from the result.
*/
resources = resources.drop lastHandledIndex + 1
} else if (options.pagedResultsOffset) {
/**
* Discard resources from the beginning of the result set according to the requested offset.
*/
resources = resources.drop options.pagedResultsOffset
}
/**
* Capture the number of remaining resources to be handled in subsequent paged results search requests.
*/
remainingPagedResults = resources.size() - options.pageSize
/**
* Get resources for the requested page size.
*/
resources = resources.subList 0, Math.min(options.pageSize, resources.size())
/**
* Set pagedResultsCookie if there are still resources remaining to be handled.
*/
if (remainingPagedResults > 0) {
pagedResultsCookie = resources?.last().uid.bytes.encodeBase64Url().toString()
}
resources
}
/**
* Process and handle resources.
*
* @param resources java.util.ArrayList
* A list of org.apache.groovy.json.internal.LazyMap instances,
* each representing a resource object for an object class.
* @param getResourceData groovy.lang.Closure
* Returns a single resource data in the format matching the object class schema.
* @return null
*/
def handleResources = { resources, getResourceData ->
/**
* Process resources to match the object class schema,
* and apply search criteria included in the request.
*/
resources = filterResources resources, getResourceData
def pagedResults = options.pageSize && options.pageSize > 0
/**
* Sort resources if sorting and/or paging are requested.
*/
if (options.sortKeys || pagedResults) {
resources = sortResources resources
}
/**
* Page resources if paging is requested.
*/
if (pagedResults) {
resources = pageResources resources
}
/**
* Add each retained resource to the result of search operation.
*/
resources.each { resource ->
handler {
uid resource.uid
id resource.id
resource.each { entry ->
if (!['uid', 'id'].find { it == entry.key }) {
attribute entry.key, entry.value
}
}
}
}
}
/**
* Handle source data for each supported object class.
* @see {@link https://backstage.forgerock.com/docs/openicf/latest/_attachments/apidocs/org/identityconnectors/framework/common/objects/ObjectClass.html}
*/
switch (objectClass.objectClassValue) {
case 'users':
/**
* Use sample data in JSON format.
*/
def json = new File('/var/lib/rcs/users.json')
def resources = json.exists() ? (jsonSlurper.parse(json)).Resources : []
/**
* Get a resource data in the format matching the object class schema.
*
* @param resource org.apache.groovy.json.internal.LazyMap
* Represents a resource object.
* @return java.util.LinkedHashMap
* A resource object in the format matching the object class schema.
*/
def getResourceData = { resource ->
[
uid: resource.id,
id: resource.userName,
active: resource.active,
displayName: resource.displayName,
givenName: resource.name.givenName,
middleName: resource.name.middleName,
familyName: resource.name.familyName,
primaryEmail: (resource.emails.find { it.primary })?.value,
secondaryEmail: (resource.emails.find { !it.primary })?.value
]
}
handleResources resources, getResourceData
break
case 'groups':
def json = new File('/var/lib/rcs/groups.json')
def resources = json.exists() ? (jsonSlurper.parse(json)).Resources : []
/**
* Get a resource data in the format matching the object class schema.
*
* @param resource org.apache.groovy.json.internal.LazyMap
* Represents a resource object.
* @return java.util.LinkedHashMap
* A resource object in the format matching the object class schema.
*/
def getResourceData = { resource ->
[
uid: resource.id,
id: resource.id,
displayName: resource.displayName,
members: resource.members,
schemas: resource.schemas
]
}
handleResources resources, getResourceData
break
default:
throw new UnsupportedOperationException(operation.name() + ' operation of type: ' + objectClass.getObjectClassValue() + ' is not supported.')
}
/**
* Return the last handled resource reference of the current search operation.
* Only pagedResultsCookie is currently supported for a Groovy Toolkit connector;
* hence, the required remainingPagedResults argument is populated with -1.
* @see {@link https://backstage.forgerock.com/docs/openicf/latest/_attachments/apidocs/org/identityconnectors/framework/common/objects/SearchResult.html}
*/
new SearchResult(
pagedResultsCookie,
-1
)
} catch (UnsupportedOperationException e) {
log.error e.message
/**
* Preserve and re-throw the custom exception on unrecognized object class.
*/
throw e
} catch (e) {
log.error e.message
throw new UnsupportedOperationException('Error occurred during ' + operation + ' operation')
}
##Scripted Groovy Connector (Toolkit) > Test Script
A test script implements the test operation. In scripted Groovy connectors, the test operation always validates the connector configuration first; if a test script reference has been found in the configuration, the script is executed as well.
The test operation is called by IDM at the time a connection is registered, and an admin UI can call it at different times in the connection life cycle. As described in the External system status doc, you can also initiate the test operation via IDM’s APIs.
This means that you have an option to use a test script for any connection validation that your particular use case requires. One common application is checking the data source availability.
To indicate a failure, the test script must throw an exception. If available, the exception should be a specific one, or you could throw a generic ConnectorException.
For example:
TestScript.groovy
/**
* Defined variables:
* operation org.forgerock.openicf.connectors.groovy.OperationType
* The SEARCH operation type.
* configuration org.forgerock.openicf.connectors.groovy.ScriptedConfiguration
The connector configuration properties.
* @see {@link https://backstage.forgerock.com/docs/openicf/latest/connector-reference/groovy.html#groovy-connector-configuration}
* log org.identityconnectors.common.logging.Log
* Logging facility.
* @see {@link https://backstage.forgerock.com/docs/openicf/latest/_attachments/apidocs/org/identityconnectors/common/logging/Log.html}
*/
def usersJsonFile = new File('/var/lib/rcs/users.json')
if (!usersJsonFile.exists()) {
throw new MissingResourceException('Resources not found.', operation.name(), 'users.json')
}
If no exception is thrown, the response JSON will contain an “ok” key
populated with true.
If there is an exception, the “ok” key will be populated with false
and accompanied with an error message that you specified in the
exception.
For example:
IDM Admin Browser Console
(async function () {
var data = await $.ajax('/openidm/system/groovyCore?_action=test', {
method: 'POST'
});
console.log(JSON.stringify(data, null, 4));
}());
{
"name": "groovy",
"enabled": true,
"config": "config/provisioner.openicf/groovy",
"connectorRef": {
"connectorHostRef": "rcs",
"bundleVersion": "1.5.20.15-SNAPSHOT",
"bundleName": "org.forgerock.openicf.connectors.groovy-connector",
"connectorName": "org.forgerock.openicf.connectors.groovy.ScriptedConnector"
},
"displayName": "Scripted Groovy Connector",
"objectTypes": [
"groups",
"__ACCOUNT__",
"__ALL__",
"users"
],
"error": "Resources not found.",
"ok": false
}
If supported, the error will also be displayed in the UI.
Note that a test script will have access to the connector’s
configuration. A test script for Scripted SQL connector will also have a
connection binding representing the JDBC data source. A test script
for Scripted REST will have connection and customizedConnection
bindings representing the HTTP client and its decorated version injected
into the scripts for connecting to the REST interface.
##Conclusion
This writing have covered some basics of developing a Groovy Toolkit-based connector for a Java Remote Connector Server, which can help use cases when an existing connector solution cannot be easily adjusted to meet particular requirements.