Migrating Data to ForgeRock Identity Cloud
Author: |
Patrick Diligent |
Created at: |
May 2023 |
Updated at: |
Apr 2024 |
ForgeRock Identity Cloud
Migrating Data
By Patrick Diligent
INTRODUCTION
When it comes to migrate to ForgeRock Identity Cloud from an on-premise deployment, there are several facets that need to be taken into consideration:
-
Migrating configuration and customisation scripts, especially when migrating from an on-premise ForgeRock solution.
-
Revisiting the current authentication and authorisation flows for a best fit within the Identity Cloud architecture, and determine the optimal path forward.
-
Inevitably, build the data model for Identity Cloud. This has some dependencies with the previous points, so this is an incremental task, refining the design while migrating applications one by one.
-
Finally, but not the least, actually moving the data to Identity Cloud, applying some transformation, without interrupting the current production system and keeping data in sync between the two sites.
We are going to focus here mainly on the last point, the “how” of migrating data. At this stage we assume that the data model design for Identity Cloud is reasonably stable, however, this topic on its own would deserve its own article.
SELECTING THE STRATEGY
The optimal migration strategy depends upon the following criteria:
-
How large is the data to transfer?
-
How much disruption is the business ready to accept? Perhaps, no downtime at all is permitted.
-
What is the level of data complexity?
-
Is the data in a good state?
-
Where is the data master copy residing? Is it fragmented, partitioned over multiple systems, or does it reside at a single location?
-
Are you planning a dual deployment until on-premise can be decommissioned (incremental, live migration), or switch over once the migration is complete? You might even consider a big bang, planning downtime to migrate all, then switch over to Identity Cloud.
-
Should updates to ForgeRock Identity Cloud be propagated back to on-premise?
-
Can the on-premise deployment be altered/upgraded to support the migration?
-
Where should the reconciliation processing occur? In Identity Cloud, on-premise, or some intermediate system?
-
What are the password requirements?
Here are below the main methods by which data can be migrated, in the order of relevance:
-
Identities Bulk Import (CSV)
-
Reconciliation
-
managed REST API
Answering those questions above will help choose the proper migration approach.
Identities Bulk Import
You will find detailed information about bulk import in ForgeRock Identity Cloud Documentation.
This strategy suits well when performing a one time migration before a switch over, and with a reasonably small dataset. There is no limit to the overall size, however, a single CSV file is limited to 50M, therefore larger dataset need to be split in several CSV chunks, and imported one by one. This obviously increases the complexity (creating CSV files and feeding them to the bulk import endpoint) and increases as well the migration time.
Also this method may not be relevant with complex data structure, or when transformations need to be applied - customisation scripts are required in this case - so it increases the complexity of the solution - and it may not be possible at all if the data complexity is too high. Also, the target resources are limited to User, Role and Assignment.
Bulk Import at its core is actually a reconciliation. It is the simplest method of all, since there is no need to configure a mapping. But when it can’t be applied due to the data complexity, inability to generate the CSV from the data repository, or data size being too large, then the next logical option is reconciliation.
Reconciliation
If you are not familiar yet with reconciliation, I would recommend reading about Sync Identities in the ForgeRock Identity Cloud documentation to make the best of this section.
First we need to identify the integration points in the on-premise deployment where data can be synchronised from . Each integration point will fall into one of the following categories:
-
There is an existing standard connector for this resource
-
There is no standard connector, possibly a custom connector needs to be developed
Luckily, the on-premise solution is a ForgeRock deployment, in which case the synchronisation points can be ForgeRock Directory Server, or even Identity Management, if any of those hold the data authoritative copy.
Connectors
Reconciliation is relying on the Provisioning Service, which makes the
external resource accessible via CREST (Common REST). A resource is
identified by a resource type - a unique name that identifies the
channel by which the data transits - for example “ldap”, the object type
(for example “account”, or “group” in the LDAP context) and some id to
reference resources within the object type (this is the “entry-uuid” in
the directory server context). For example, in the LDAP case,
/system/ldap/account/<some id> will uniquely identify an entry within
the directory server.
Identity Management connectors are listed here: IDM Supported Connector.
When it comes to Identity Cloud, these connectors can be classified under different deployment models [See Connector Reference ] :
-
Built in Connectors [ Identity Cloud built-in connectors ]. The connector is executing in ForgeRock Identity Cloud.
-
Remote connectors [Remote Connector Server (RCS) connectors ]. The connector is executing in a remote server hosted on-premise.
-
Within remote connectors, some are already bundled within the Remote Connector Server (RCS) [RCS bundled connectors], while the remaining can be downloaded from ForgeRock Backstage [Additional connectors].
Why a Remote Connector Server?
As you may have noticed, the built in connectors involve an HTTP connection to an external, public API. Identity Cloud can’t access any resource within the organisation firewall, this is where the Remote Connector Server comes handy.
The Remote Connector Server is deployed on premises. It establishes a secure websocket connection to Identity Cloud, thus working around the organisation firewall. It is in fact the most secure way of exchanging data with Identity Cloud. Once the server has established the connection, it receives the connector configurations from Identity Cloud and initialises the connectors - loading the bundled java archives. So configuring the connector involves:
-
Creating the configuration in Identity Cloud for the Remote Connector Server [ Remote Connector Configuration ]
-
Ensure that the connector type has the corresponding bundle installed with the connector server,
-
Provide the connector configuration via Identity Cloud administration.
Note that in the case of a Groovy connector, the groovy scripts reside local to the Remote Connector Server.
Connectors also have the ability to execute scripts in their context - outside of the CRUD operations - giving the flexibility to access any private, internal on-premise API. This can come handy when bi-directional synchronisation is implemented, and the reverse synchronisation requires an update via an internal API. You can find more about this in this article: using-the-remote-connector-server-to-access-on-premises-apis-from-identity-cloud .
OOTB Remote Connectors
You can find the list there : RCS bundled connectors. Among those, the LDAP Connector is probably one of the most useful, as most organisations are deploying a directory server to store identity profiles.
The next in line is the Database Table Connector, as there is a great chance an RDB holds the data. However, it is limited to one table, or view - in other words, it will hardly handle complex data. To handle complex data, a view can be created as a join between different tables, however in this case updates to the RDB won’t be possible. Therefore to handle a complex model, the Scripted SQL connector is the best fit…
Next the Scripted REST connector comes handy to handle data that is accessible via an API over http.
Among the remote connectors, Groovy connectors (Scripted REST and Scripted SQL) are particular as they involve writing Groovy scripts, therefore, require Groovy development skills, knowledge of the Identity Connector Framework (ICF) and as a consequence, it will extend the project timeline. As such, these are not fully OOTB as they require customisation.
Finally, another option that will not be discussed here, is the development of a Custom Java Connector, which is a higher up level in the development effort.
Selecting the source
Now that we have some idea of the different connector categories, how to select the proper provisioning strategy? These are the main factors:
-
How is the data accessible?
-
How is the data distributed?
-
What is the effort in configuring the connector?
Answering the question how is the data accessible is to examine each data store and determine whether a connector is available, is it out of the box, or does it need to be developed?
How is the data distributed is about finding whether there is a single source or whether it is completely fragmented.
What is the effort is about determining the organisation skills in connector development. Understanding the effort required in configuring an OOTB connector. And be able to weigh the project costs between moving the data to a single source accessible with an OOTB connector (for example, a directory server), and development cost to access an existing single source but only with a custom developed connector (e.g groovy connector).
For example in a traditional ForgeRock platform deployment, the AM identity store, provisioned by Identity Management, holds a subset of the data from the IDM repository. It is possible to outline two different strategies here:
-
Since the complete data is held by IDM, use a scripted REST connector to reconcile to Identity Cloud is natural fit. The effort is in developing the Groovy scripts, however the impact to the existing production system is minimal.
-
Deploying an LDAP Connector to the Identity Store is easier, however some of the missing data needs to be pushed to the directory server, therefore, requiring adding schema and so on. No development is involved, but there is a major impact to the production system.
These scenarios are examined further in this article. There is no best approach here, it all depends upon the data structure, the organisation skills, and the project timeline.
Live updates
If downtime is an option while migrating data, and the data size is such that the migration can be performed within an acceptable time, then there is no need to propagate live updates during the operation, since the production system is taken off load.
When downtime is not acceptable, or the data size is such that migration can’t be performed in a reasonable time, then the migration has to be performed while the system is still under load. Therefore, live updates should be propagated during this operation.
Live updates is the most tricky part in the migration strategy, and is the sole reason why it is hardly done without readying the production deployment for it. So if downtime is allowed, and data is reasonably small to fit the window, then this will definitely make your life easier!
There are two main methods to propagate live updates:
-
Implicit Synchronisation. The Identity Management on-premises propagate updates applied to the managed object through a reconciliation mapping to Identity Cloud,
-
Livesync. The connector configured in Identity Cloud is polling the on-premises resources for changes.
Implicit Synchronisation
The main drawback with implicit synchronisation is that the on-premise production system must be altered to support it, adding a connector and a reconciliation mapping. Furthermore, this adds some extra load and overhead to the on-prem server. This is particularly true with Scripted REST connecting to IDM in the cloud. This is unavoidable, since IDM does not produce a change log, and filtering with timestamps is not possible, therefore livesync can’t be supported in this case.
Livesync
This is the ideal solution, as it does not induce extra load or overhead to the on-premises system. On paper, it does not necessitate altering the configuration. The last statement holds true if for example the AM identity Store already contains the complete data view. However, in most cases, this is not true. As explained above, the external resource probably needs to be extended to export the complete authoritative data, however once this is achieved, livesync comes free with connectors that support it, just turn it on when reconciliation has been configured.
How does it work? A livesync is launched by a schedule [Schedule synchronization], and runs until all latest changes have been retrieved. livesync relies on a sync token to keep track of the last change. The sync token is increased at each record retrieval, and at the end of a livesync run, when all changes have been captured, the last seen sync token is persisted.
There two main ways by which livesync can track changes:
-
With a changelog (where the sync token is the changelog number),
-
With a timestamp
The changelog is the ideal solution, as it covers all the CRUD operations. The timestamp method does not allow DELETE operations capture.
The ForgeRock directory server produces a change log. There is some care needed in configuring the ForgeRock Directory Server though, to ensure that the changelog contains all the changes that have not yet been retrieved, while you don’t want it too large to avoid filling the disk. This has all to do with the replication server purge delay and history state.
For some other directory vendors the change log is not supported, therefore livesync falls back to using a timestamp based sync token. In this case, delete operations are not detected. This is also often the case with RDBs, where timestamp is the only available option.
Case Studies
Let’s look now at some interesting migration scenarios, involving the most common source of data:
-
ForgeRock Directory server and the LDAP connector,
-
IDM REST, and the Scripted REST Groovy connector,
-
Relational Database, and the Database Table Connector or Scripted SQL Connector.
You will notice that the diagrams in these studies show bi-rectional synchronisation for the sake of completion. Your project might just need to synchronise to Identity Cloud one way. However, if synchronising back to on-premise is required (as is often when keeping both environments co-existing), then it is recommended that you read further in the article the section on Bi-directional synchronisation - this will avoid some headaches when you’ll have to implement it.
Directory Server as the synchronisation source
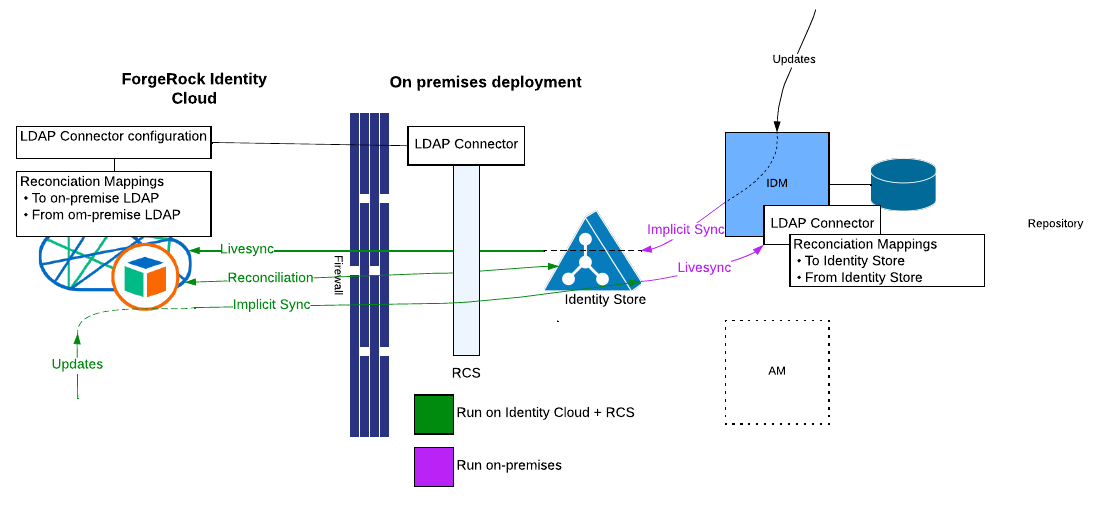
Why use the ForgeRock Directory Server? The answer comes with two
compelling reasons:
-
The LDAP Connector is available out of the box.
-
Live Updates are captured with Livesync. This is important if any downtime is unacceptable while migrating.
By comparison, Scripted REST to Identity Management can’t provide livesync, so the solution requires Implicit Synchronisation, and therefore, adding extra load to the on-premise deployment. With an LDAP connector, all processing happens in Identity Cloud and on the Remote Connector Servers installed on-premise.
Chances are the solution is already pushing user identities to the AM user store. In order to migrate the complete data, it has to be all provisioned to the directory server, which therefore needs to be extended.
In a nutshell these are the overall tasks:
-
Extend the directory server schema to receive the additional data.
-
In the LDAP connector configuration, add the object types and properties in line with the new schema.
-
Design/Alter the reconciliation mappings to sync the additional data to the directory.
-
Deploy the Remote Connector Server
-
Deploy the same LDAP connector configuration in Identity cloud (the Object Types, and Server URL are same, at least)
-
Design the mappings to reconcile from the directory server to Identity Cloud.
-
Turn on livesync in Identity Cloud, then perform a reconciliation.
-
If synchronising back changes from Identity Cloud:
-
Add reconciliation mappings in the IDM on-premise to reconcile from the directory server.
-
Add reconciliation mappings in Identity Cloud to sync the data to the directory server.
-
Ensure that Identity Cloud and on-premise IDM use different accounts to apply updates, and on both sides, configure modifiersNamesToFilterOut to prevent synchronisation loops.
-
Turn on livesync in the on-premise IDM, then perform a reconciliation.
-
Why turn livesync on first, then start the reconciliation? This is because the first time livesync run, it computes the sync token as the latest change number seen in the directory server changelog. If update traffic is still happening, then if reconciliation is started first followed by livesync, there is a gap where some changes could be missed.
About Synchronisation loops: this is all explained later in the Bi-Directional Synchronisation section.
Extending the directory server entails:
-
Assigning an Object Class for each Managed Object, and associated attributes, and possibly, an Object Class to handle relationships.
-
Possibly create dedicated branches for each object class,
-
Create a connector for each object class/branch in the LDAP connector configuration.
-
In the mapping to the directory server, provide a property for the Object Class and a transform that sets it to the correct value. The DN should also be computed to target the correct branch. There is one mapping for each object class.
-
In the LDAP connector configuration, ensure that the proper object classes are included in the search filter.
That solution will work well for a simple data structure, and will become increasingly difficult for more complex data.
IDM REST as the synchronisation source
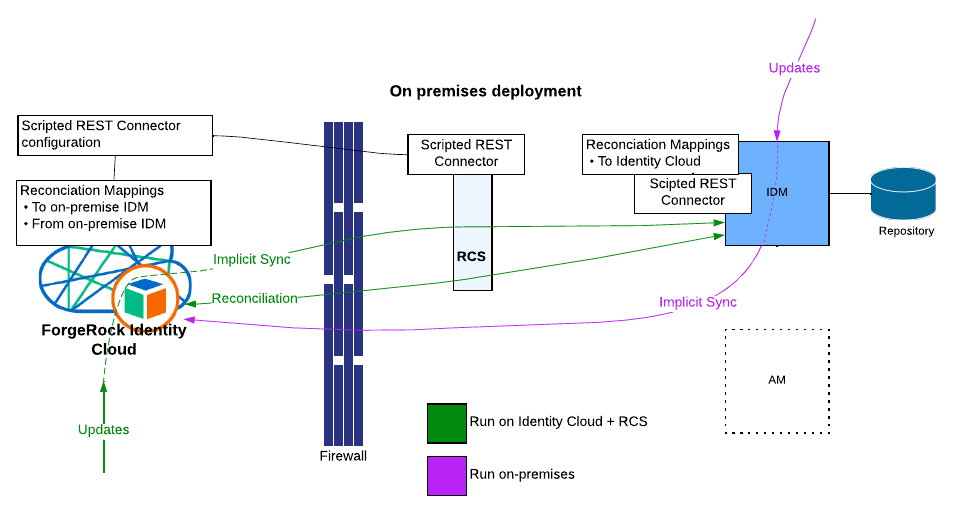
There is a high probability IDM is the authoritative source of data in common ForgeRock deployments, and therefore this method will allow direct migration from the IDM server.
This is has been documented in the ForgeRock Knowledge Base way before the Migration service was introduced, to migrate data from a 3.1.0 IDM instance to IDM 4: Knowledge - ForgeRock BackStage.
Notice here that this was based on the Groovy Scripted CREST connector. The Scripted CREST connector is not anymore available in the latest IDM releases (7.x), and therefore, not available for Identity Cloud. Instead, the Scripted REST connector must be used.
The support for past releases is the following:
-
up to 6.5: Scripted CREST and REST connectors are supported.
-
6.5.1: Scripted REST only.
-
7.x: Scripted REST and IDM remote service available.
The external IDM service has made its way in IDM 7, and it is not necessarily well known, but nonetheless is very useful. Under the hood, the external IDM service embeds a CREST Connector and complies with the Provisioning Service interface. What does this mean? It means that reconciliation can operate through the IDM remote Service WITHOUT having to provide groovy scripts and connector configuration. Isn’t it great? The catch is that you won’t be able to use the service in Identity Cloud as the on-premise private network is unreachable, and therefore, reconciliation has to be initiated from the on-premise instance, which you now understand, has to be an IDM 7.x instance. So, it might be worth considering migrating the on-premise IDM to the latest.
Let’s first look at the Scripted [C]Rest option. This is shown in the diagram above. These are the steps in designing the solution:
-
Deploy the Remote Connector Server on-premise
-
Deploy the Groovy Scripted Rest connector scripts (to be developed) local to the RCS and add a connector configuration in Identity Cloud.
-
Provide the reconciliation mappings to and from on-premise.
-
Livesync is not available here, because there is no handle in the IDM data that enables us to filter the latest changes - unless the IDM schema is instrumented, this can be done, but a lot of work and intrusive as well. So the natural solution here is to rely on implicit synchronisation.
-
Install a Groovy REST (or CREST) connector on the on-premise IDM instance.
-
Provide reconciliation mappings to Identity Cloud, turn off “enableSync”.
-
-
Turn on enableSync for the on-premise IDM, then start the reconciliation from Identity Cloud (note that this assumes Identity Cloud is not receiving updates yet).
The following can help you in this endeavour:
-
Bitbucket (migrating from 5.5 - with CREST)
-
migrating-identities-to-identity-cloud-with-scripted-rest (6.5.x to IDC with REST)
For 6.0, any of the samples above apply - with little modification.
For 7.x, using the external IDM service is the solution. In this case,
no more Groovy scripts and connector configuration - just provide the
mappings and the configuration for the external IDM service. However, if
updates in Identity Cloud have to be propagated back to on-premises,
then a Scripted REST Connector is still needed at the Identity Cloud
side.
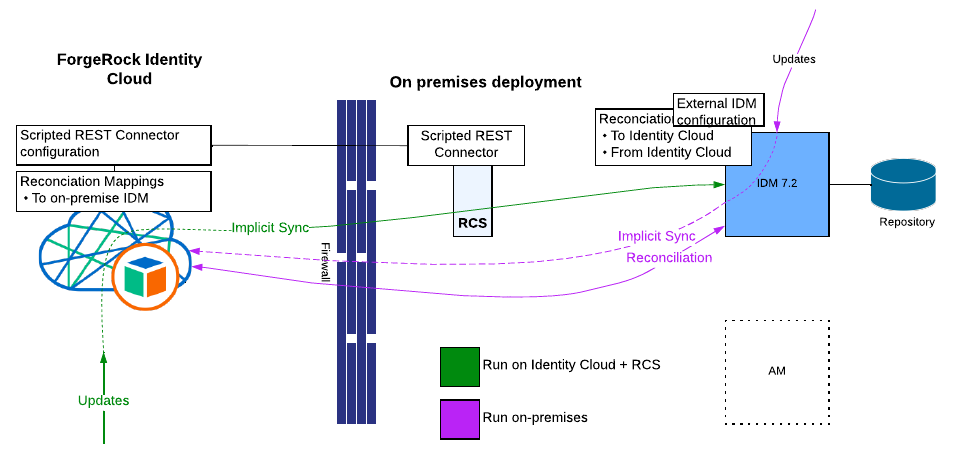
Here is below an External service configuration example
(external.idm-idc.json) - you need to create an OAuth2 client in
Identity Cloud and set the proper permissions - instructions at :
Authentication
through OAuth 2.0 and subject mappings :: ForgeRock Identity Cloud Docs
{
"instanceUrl": "https://&{idc.tenant.host}/openidm/",
"authType": "bearer",
"clientId": "idm-client",
"clientSecret": "password",
"scope": [
"fr:idm:*"
],
"tokenEndpoint": "https://&{idc.tenant.host}/am/oauth2/realms/root/realms/alpha/access_token"
}Then the reconciliation mapping source or target is configured with:
external/idm/idc/managed/alpha_user
Relational Database as the synchronisation source
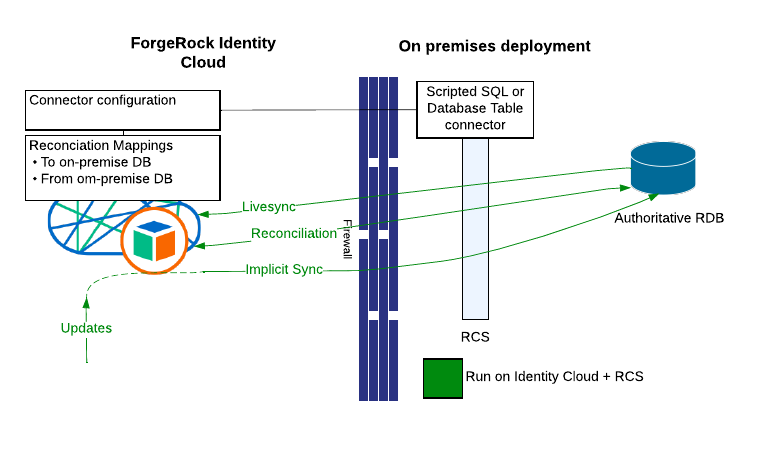
It is often the case that a relational database holds the authoritative data, in which case using the Database Table Connector or the Scripted SQL Connector is a compelling option.
A Database Table Connector can be used in the following conditions:
-
There is only one table in the model
-
Or a view can be created to aggregate all tables and one way synchronisation is sufficient (e.g no updates back to the RDB).
-
The data model is relatively simple.
When none of the above conditions are met, the fallback is to use of the Scripted SQL Connector. This involves accrued development, however the IDM distribution includes a sample that can be easily adapted. This article also discusses the development of a Groovy connector developing-a-groovy-connector.
Note that it is likely that a timestamp based livesync can only be implemented here, in which case DELETE operations can’t be propagated; if those need to be taken into account, then some extra functionality outside of livesync/reconciliation needs to be considered.
A ForgeRock deployment on-premise is not being shown in the diagram, it is intentional - as this case is possibly the best option in migrating a non-ForgeRock deployment/home built solution - it likely relies on a central RDB.
The Bi-Directional Synchronisation case
Up to now, we have been talking about a one way synchronisation, from on-premises to Identity Cloud. This works Ok if Identity Cloud does not enter production until migration is performed and on-premises decommissioned - that’s the big bang scenario.
However, the project may plan for a more progressive and controlled approach , where applications are migrated one by one, and become operational, one by one, in Identity Cloud. This implies coexistence between two environments, on-premises and Identity Cloud, sharing the SAME set of user data. In this case, any update performed to Identity Cloud data is to be synchronised back to on-premise. And of course, an update on-premises is propagated to Identity Cloud. This works through Implicit Synchronisation, and it’s “just” a matter of adding the reverse mapping, “just” between quotes, because this is not the end of the story. In fact, bi-directional mappings are tricky, and rings the bell for disaster if not carefully designed.
There are two challenges ahead:
-
Update conflicts
-
Infinite synchronisation loops
Update conflicts
What happens if the same update is performed at the same time on both sides? This is a scenario that should be avoided at all costs, as it can be hardly corrected. The last in wins, but is that the correct outcome? In terms of data migration implementation, nothing can be done to prevent it.
The answer resides in the overall platform migration, and especially with application migration. For example, a rule of thumb would be to fully migrate the self-services to Identity Cloud first before migrating users, and then when complete, direct all users to Identity Cloud to register, change their passwords and so on.
Synchronisation loops
Picture this:
-
An update is applied in Identity Cloud.
-
which causes Implicit Synchronisation to on-premise (managed object updated)
-
which might cause implicit synchronisation to Identity Cloud
-
… potentially causing an infinite loop.
“Might” because an implicit synchronisation will incur an actual update to the resource only if the computed target (e.g after applying the reconciliation mapping to the source object) is different from the current target resource. This may happen even when the target resource have not changed, because:
-
The target object may have unreadable properties, but still computed by the mapping (a typical example: passwords)
-
The target property is an array, however, JSON lists are equal only if their elements are in the same order (contrast with LDAP, where a multivalued attribute is not ordered). Note though that with the latest IDM release (and so in the cloud) this not holds true anymore. But still valid for older on-premise IDM deployments.
-
There might be some ambiguity (or inconsistency) in processing array type values, between null, empty or undefined, or how an absent property is processed.
Note that the same scenario applies with livesync. This causes a livesync session to run indefinitely, as updates from livesync causes implicit synchronisation back to the resource, which feeds more changes for the current livesync run to process. This will give the impression that livesync is not working anymore, as now an update will take an eternity to reach the other end.
To deal with this, there are two approaches:
-
Design the mappings to guarantee that the computed candidate target is always equal to the current target when both objects are in the same state.
-
Implement a mechanism which detects the source of the change.
Implementing both safeguards is good. With the latter method, there are two places where this can be implemented:
-
In the connector
-
In the reconciliation mapping
Loop prevention in the connector
The LDAP connector has this built in, with the configuration property
modifiersNamesToFilterOut [
LDAP
Connector Configuration ]. The idea is to create an account in
Directory Server that is only used by the connector to perform updates.
By setting this configuration with the DN of the account, this ensures
that the livesync will not capture changes made by the connector. When
developing a Groovy connector, it is good to add this functionality,
however, the resource itself must make provision in the data model to
facilitate it.
Loop prevention with a reconciliation mapping
When it is not possible to filter the changes at the connector level, this can be implemented with customisations in the mapping (sync.json) and in the managed object configuration. The steps are:
-
Create a custom property in the target object in Identity Cloud, for example Alpha_User, name it for example custom_livesync_flag.
-
Create a property mapping for custom_livesync_flag with a transform script:
"source": "",
"target": "custom_livesync",
"transform": {
"globals": {},
"source": "\"START\";",
"type": "text/javascript"
}
},Anytime reconciliation or livesync updates the target in Identity Cloud,
custom_livesync_flag is set to “START”
-
Add code in the onUpdate and onCreate hooks [ https://backstage.forgerock.com/docs/idcloud-idm/latest/scripting-guide/script-triggers-managedConfig.html[Script
- triggers defined in the managed object configuration
-
ForgeRock Identity Cloud Docs] ]
if(object.custom_livesync_flag === "START") {
object.custom_livesync_flag = "YES"
} else {
object.custom_livesync_flag = "NO"
}When the object has been updated due to synchronisation, the state is set to “YES”. Otherwise, any other value causes the state to be “NO”. The object variable contains the value from the request. When sourced from reconciliation (e.g the connector), the object has the value “START”, when sourced from the IDM endpoint, the value will not be present.
-
Finally the last step is to add a condition in the reverse mapping:
"validSource": {
"globals": {},
"source": "source.custom_livesync_flag === \"NO\"",
"type": "text/javascript"
}The Password case
This topic is fairly covered in the Identity Cloud documentation: Synchronize passwords. There are basically two strategies that can be used here:
-
If the password hash is compatible with Identity Cloud, then it can be transferred as is to Identity Cloud.
-
Otherwise, the password can be captured in a journey using the Pass-through Authentication Node: Pass-through Authentication
There is though a particular case with a dual environment: password change in Identity Cloud needs to be propagated back to on premises. Passwords can’t be transmitted in clear during the reconciliation, since it is hashed in the Identity Cloud user profile. To circumvent this, the following methods can be used:
Private, Encrypted custom attribute to hold the clear text password
The clear text password can be captured and stashed in an encrypted and private custom attribute using the onUpdate and onCreate managed scripts, and decrypted on the fly when sent over via reconciliation - so in the AM journey, a patch object node updates the password through IDM, and the the clear text value gets copied to the custom attribute which encrypts it on the fly.
Script on resource to access an internal on-premises API (which could be IDM)
Propagating the password change back to on-premises could also be achieved through a Scripted REST Connector using the script on resource operation to access an internal on-premises API. This is explained here : using-the-remote-connector-server-to-access-on-premises-apis-from-identity-cloud. In the change password or forgotten password journey, create a Scripted Decision Node to invoke the operation via the IDM System endpoint.
About relationships
Complex data models involving several custom managed objects with relationships is common for on-premise Identity Management deployments. With Identity Clouds, it is possible to create custom Managed Objects, however creating relationships to other objects is not supported. The strategy in this case is to emulate the RDB design pattern: use a common attribute (foreign key) to correlate objects, and design a custom endpoint to retrieve the object and its siblings in several requests, using the “foreign key” for sub queries, and wrap the data (the object and its dependencies) into a single response.
In this context, therefore, there is no extra step required in designing the reconciliation mapping to include relationships synchronisation, other than provisioning the foreign key value.
However, in Identity Cloud users, roles and assignments are involved in relationships. In that case, building the reconciliation mappings requires extra steps. This article: migrating-identities-to-identity-cloud-with-scripted-rest and the associated repository Browse Professional Services / scriptedrestmigration - ForgeRock Stash demonstrate syncing user data with their dependencies (roles, authorization roles, assignments) to Identity Cloud using a Scripted REST connector.
Is big-bang migration avoidable?
What applies to user passwords, may apply to users as well. Remember, one strategy to migrate passwords is capturing the user credentials with an AM journey, then persist the password in the Identity Cloud user profile.
The strategy here is to migrate users when they authenticate against Identity Cloud for the first time, from within the AM journey. It still requires a connector to the on-premise system, which can be accessed from a Scripted Decision node in the AM journey. However, here no replication, no livesync, once the user is migrated, the user profile on-premise is no longer needed, everything is processed within Identity Cloud from now on.
The drawback with this method is that some users may never get migrated, because they have not signed in for a long time - and you need to know when it is the right time to cut the production system. So the strategy requires some communication with the user community to make sure it goes smoothly and timely, while optimising the production costs.
When none of the strategies above work
The approaches that have been discussed so far could be seen as the main ingredients in the migration recipe; when none of the approaches completely fits, there are still gaps, then some custom code could be needed, and these approaches slightly revised. There is a brutal, extreme approach: simply developing a custom migration solution involving reading from on-premise data, receiving change notification, and propagating to Identity Cloud using the managed endpoint; which is not necessarily recommended since this functionality is already provided by the IDM reconciliation service.
The difficulty in fact is the live updates propagation. Implementing a solution without upgrading the on-premise production is hardly possible. This is where adding some custom logic might be valuable.
This paper below examines a possible strategy that requires minimal update to the production system, in fact, just redirecting IDM traffic through an Identity Gateway layer: migrating-identities-to-identity-cloud-with-identity-gateway
This approach consists in deploying an extra IDM 7.2 instance, which connects to Identity Cloud and the on-premise server via the external IDM service. No Groovy scripts are required, and no Scripted Connector either. The IDM 7.2 server does not hold any data, just the reconciliation state (links). Live updates in the on-premise instance are captured by Identity Gateway, and replayed to the IDM 7.2 server as reconById operations. Note that this solution does not demonstrate update propagation from Identity Cloud to the on-premise instance. However, Identity Gateway can also be inserted in front of Identity Cloud and propagate the changes via the IDM 7.2 recon endpoint as well.
Consolidation
Monitoring the migration under progress is fundamental to ensure data consistency. This consists in capturing errors, analysing them, and performing individual reconciliations (reconById) for those failed records.
Having a complete knowledge of the existing data is also crucial. When designing the data model in Identity Cloud, it may include validation policies. If those are more restrictive than the data policies on-premise, then this is calling for disaster, especially with livesync. This is what happens:
-
A livesync run capture a record and forward it to the managed service
-
The update is denied as it violates a policy and the livesync run aborted
-
Next livesync run is kicked off (after x minutes) and retry the same sync, which fails again
-
And so on to reach a maximum limit.
Retrying here will not help, as the policy validation is there for good until one corrects the data, so it can take up to 20 minutes for the livesync to recover. Under high traffic, it will take an eternity for livesync to catch up if there are many policy validation occurrences.
So how do you deal with this?
-
Make sure that the Identity Cloud policy validations are in line with on-premise ones - assuming that the on-premises server enforces them and is in a good state. We have seen cases where those were in place, non the less, some test done in the past has left behind some data residue violating those policies!
-
Or, relax the policy validations in Identity Cloud during migration, then re-establish them after it’s complete. That might not be relevant for a long-term dual environment co-existence, and still invalid data has made it through to identity cloud.
-
Sanitise the on-premise data so that it wholly complies with the Identity Cloud policies.
And lastly, one good tip is to enable persisted reconciliation, so that
to keep the history after reconciliation, especially in the testing
phase. Then use the /recon/assoc endpoint to examine each
reconciliation task, eventually nailing policy validation failures, as
well as identifying any other reconciliation mishaps.
Wrap-Up
With these different possibilities, how should the best approach be selected? In a nutshell, the input is:
-
Data Size / System performances
-
Downtime Requirements
-
Project Timeline
which helps to determine which approach is suitable:
-
A single shot migration is possible (data size reasonably small, and enough provision for downtime, short-term project)
-
A long term project allows to hold a dual environment, extending the actual migration on the long run, for larger data sets, more resources to develop the customisations,
-
and there is the in-between where every aspect needs to be pondered according to all factors.
This involves examining whether:
-
The production system can be upgraded to facilitate a better migration experience to Identity Cloud.
-
The provisioning model can be reviewed to allow using a standard connector (and therefore reduce development time)
-
If project timeline allows, examine the skills required to develop a custom connector,
-
Examine further customisations to fill the gaps.
And run several cycles, reviewing the requirements to lower the constraints, re-evaluating the project against the above criteria, until it can be confidently executed.
And of course, a lot of creativity helps!